duration <- read_csv("data/coretta2018/token-measures.csv") |>
rename(
c2_voicing = c2_phonation
) |>
mutate(
c2_voicing = factor(c2_voicing, levels = c("voiceless", "voiced")),
vowel = factor(vowel, levels = c("a", "o", "u")),
c2_place = factor(c2_place, levels = c("coronal", "velar"))
) |>
drop_na(v1_duration)
contrasts(duration$vowel) <- "contr.sum"Including group-level effects in brms
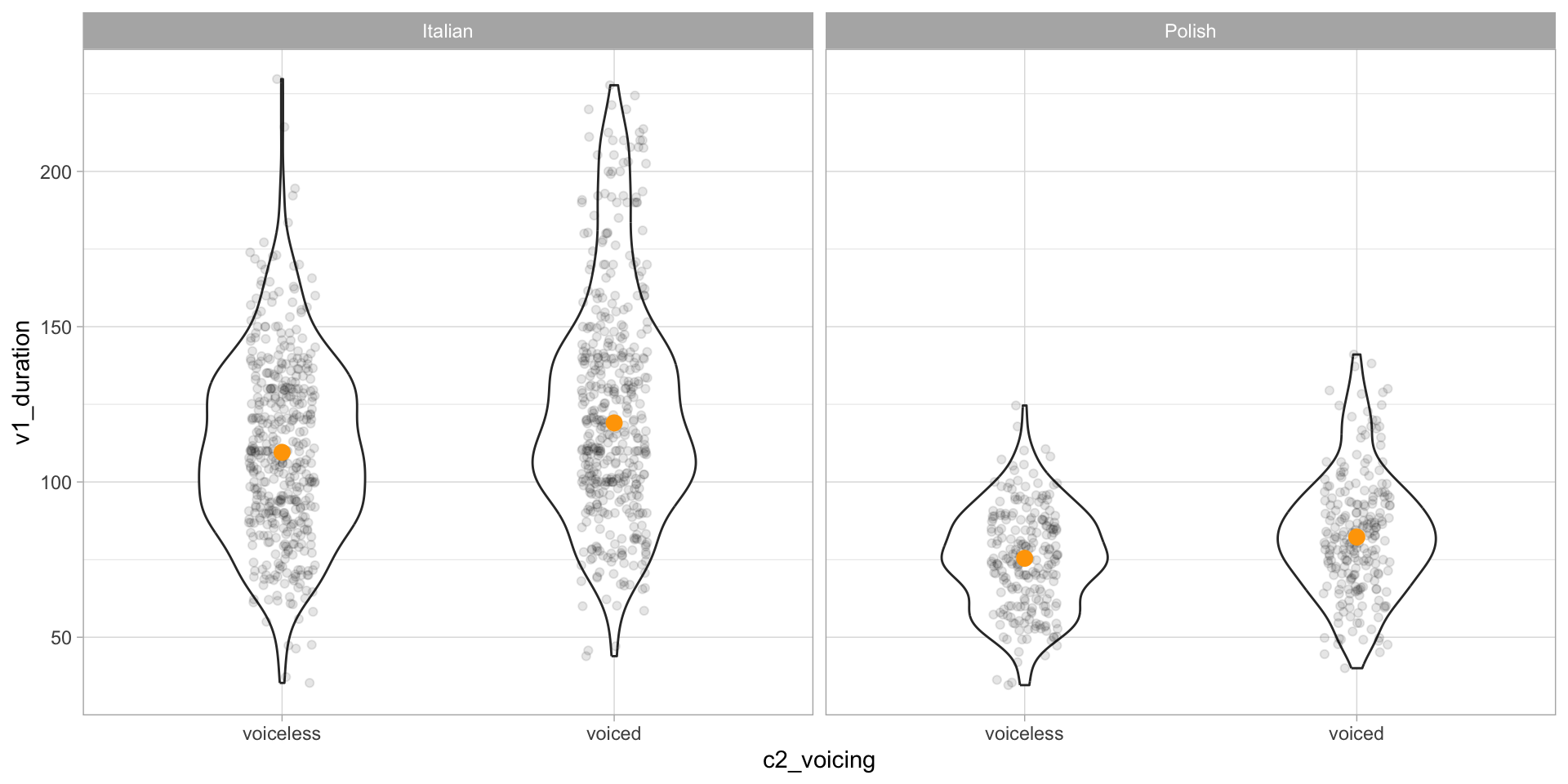
Vowel duration by C2 voicing
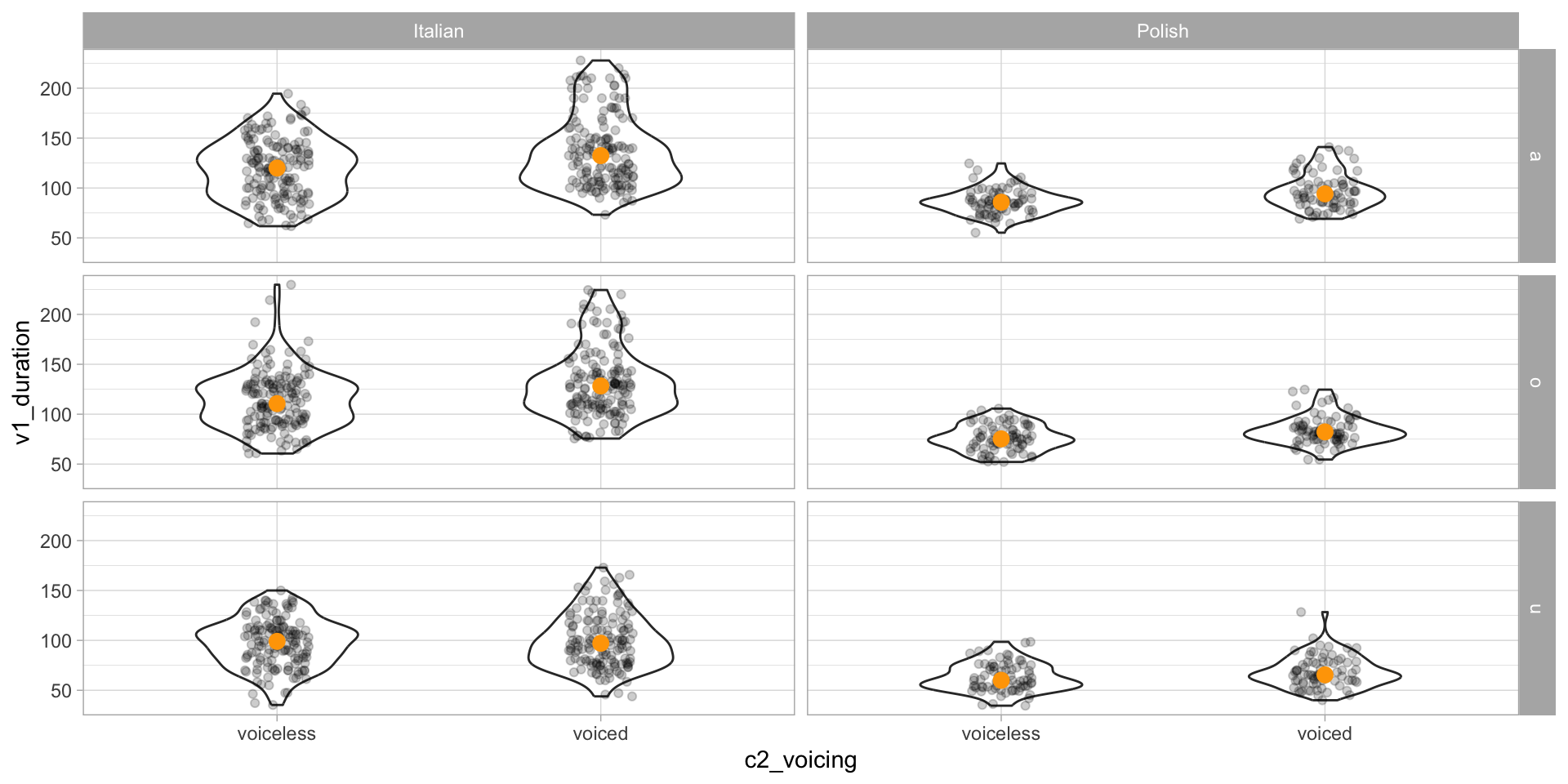
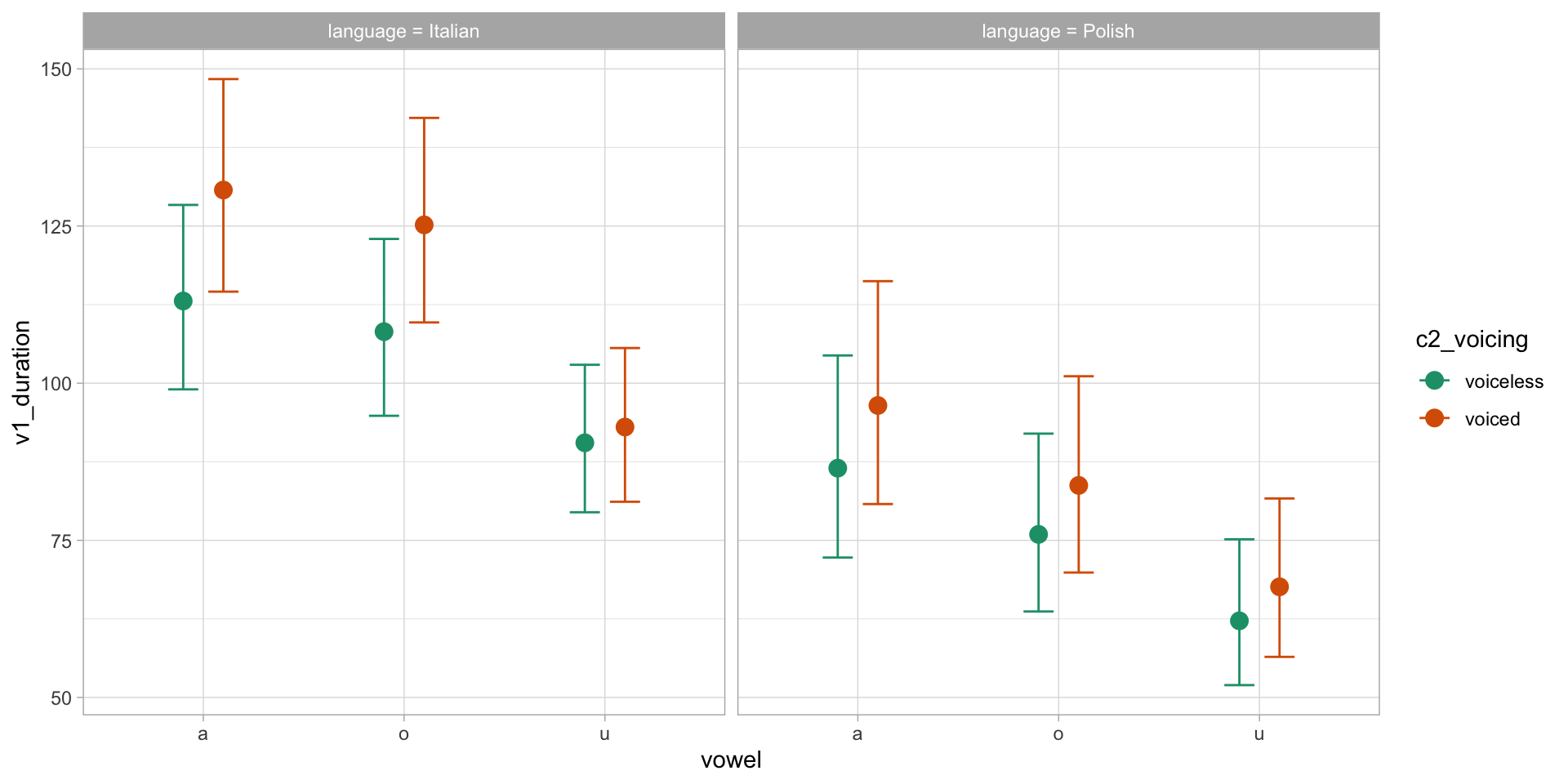
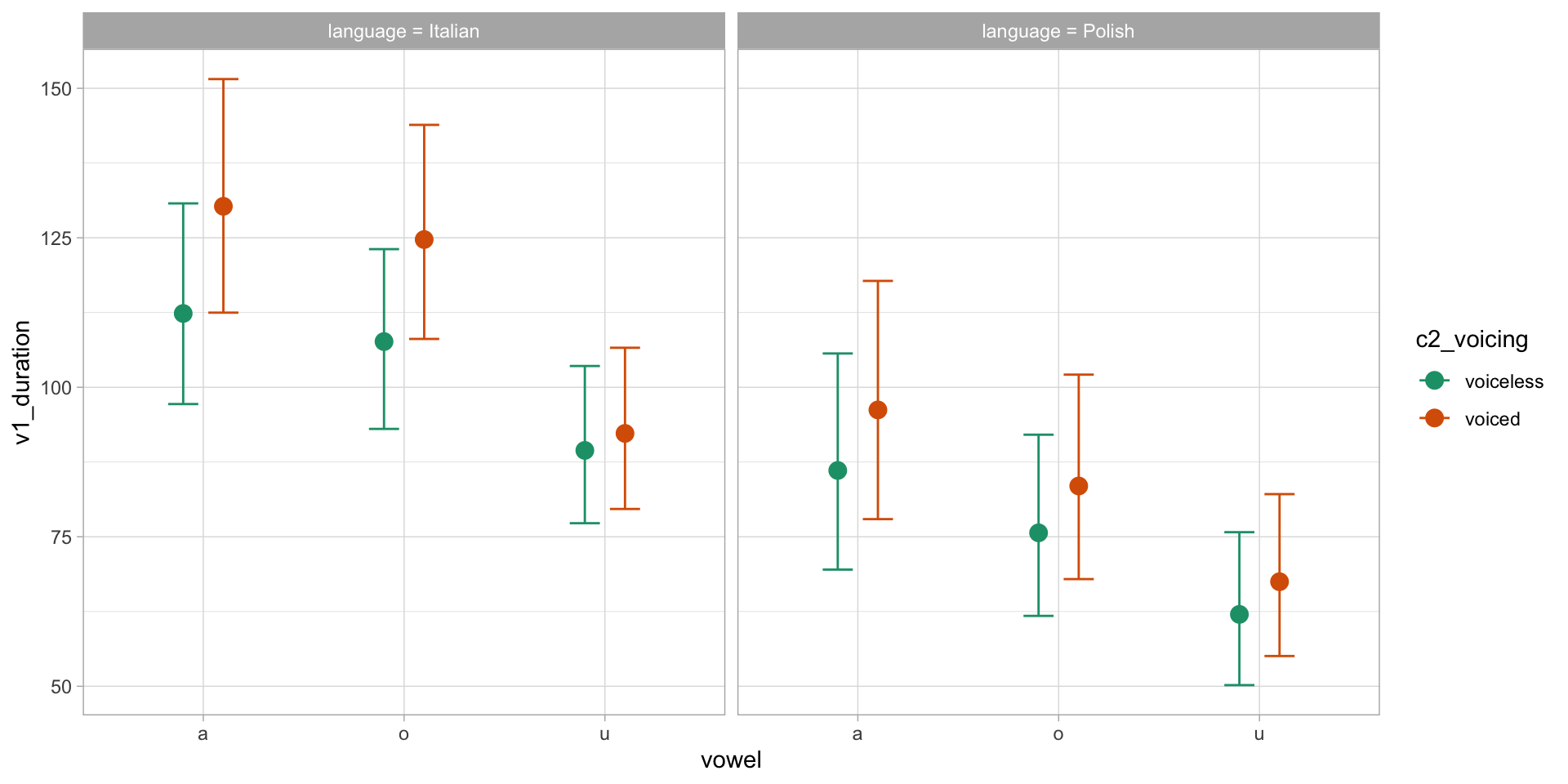
Vowel duration by C2 voicing and vowel
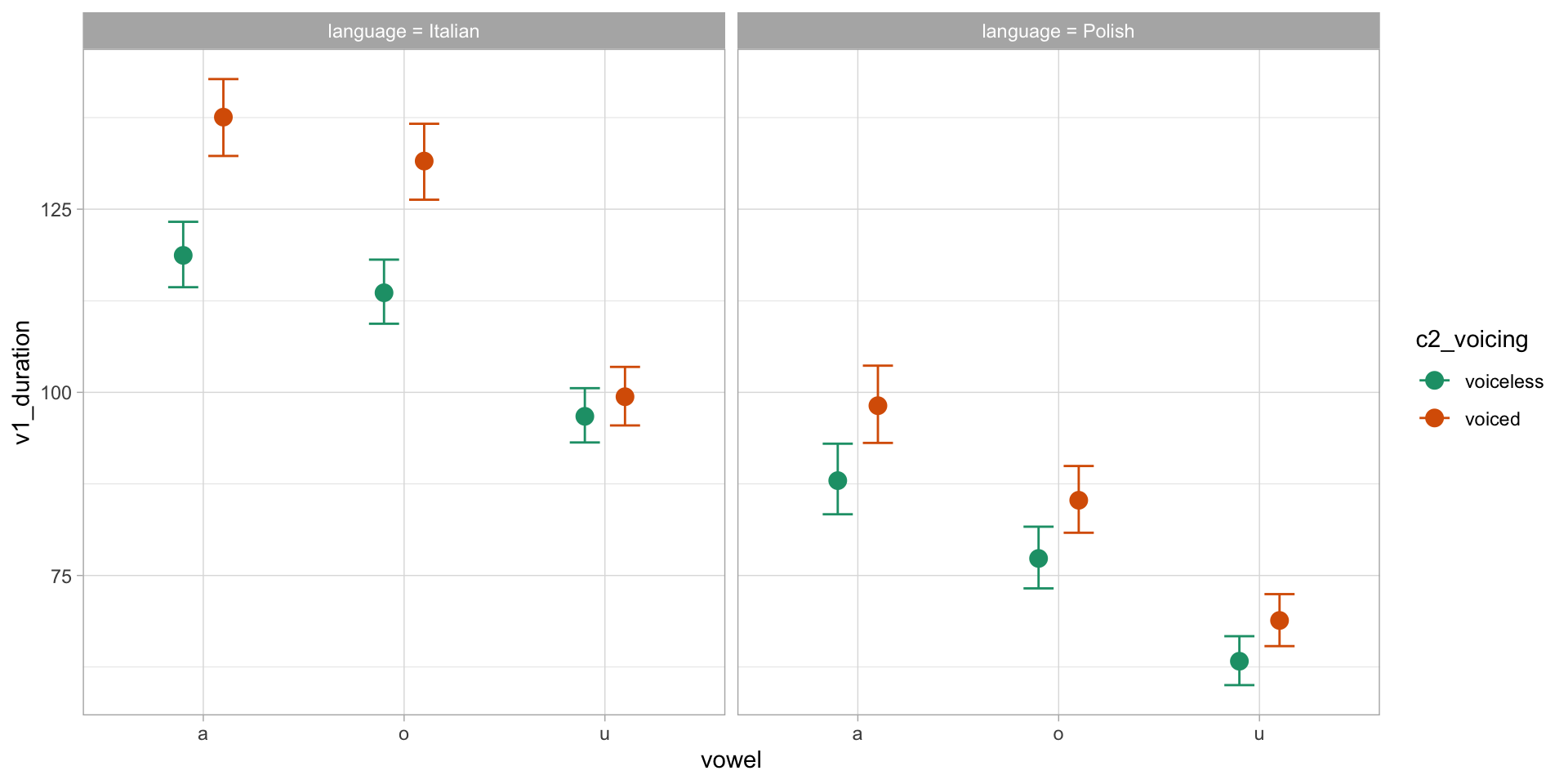
Conditional predictions of vowel duration
Posterior probability distributions of coefficients
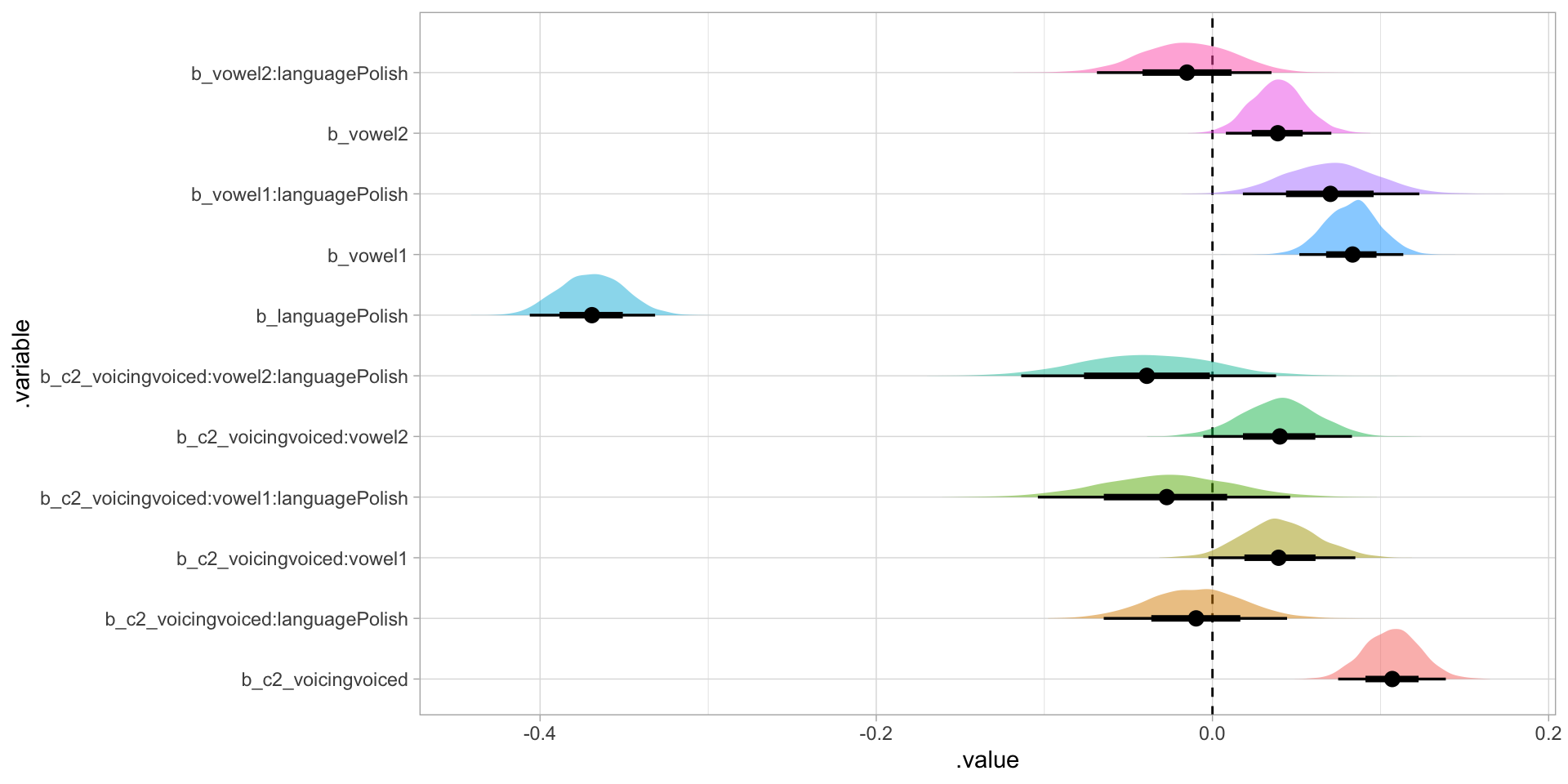
Posterior probability distributions of effect of voicing

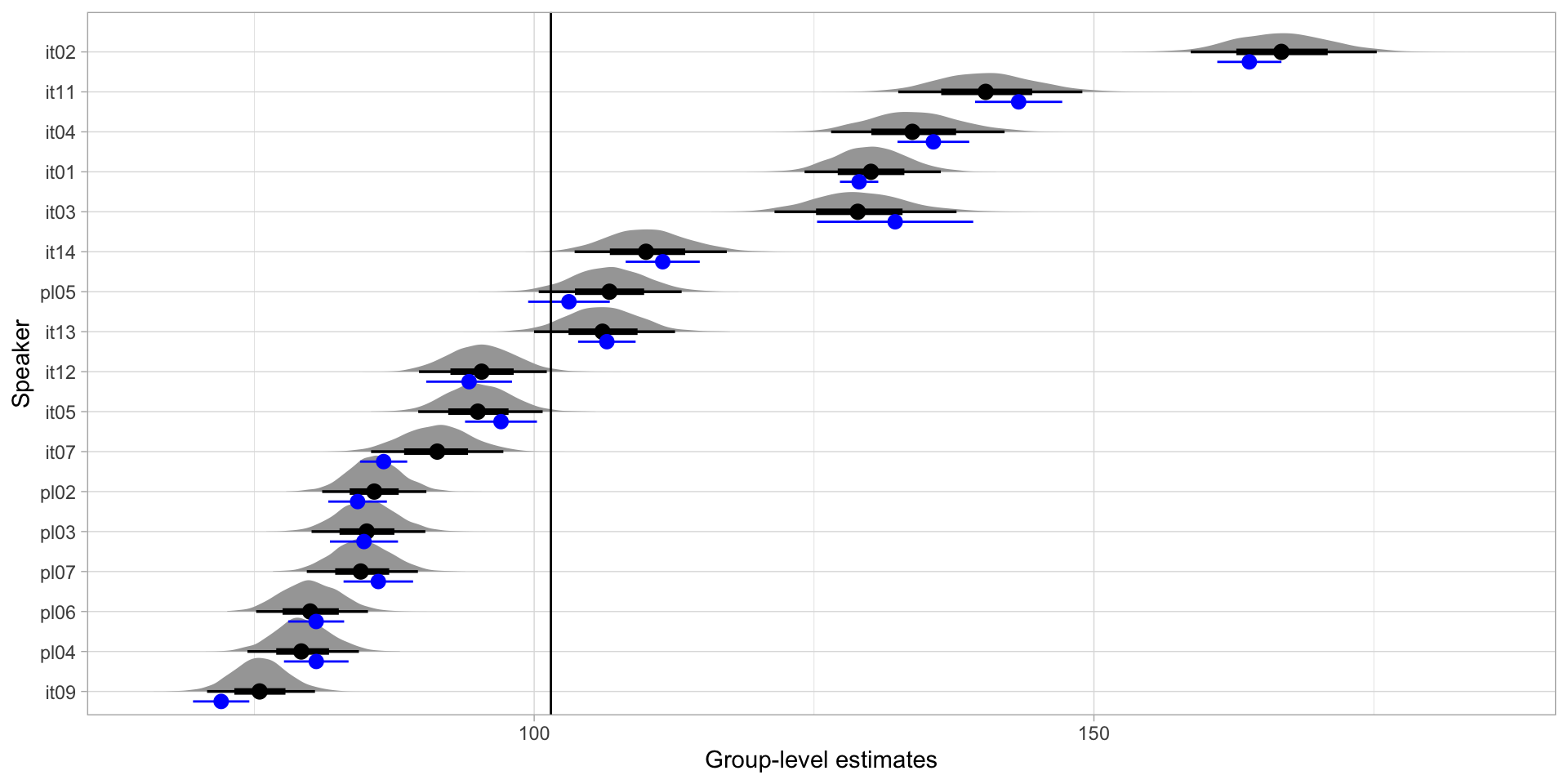
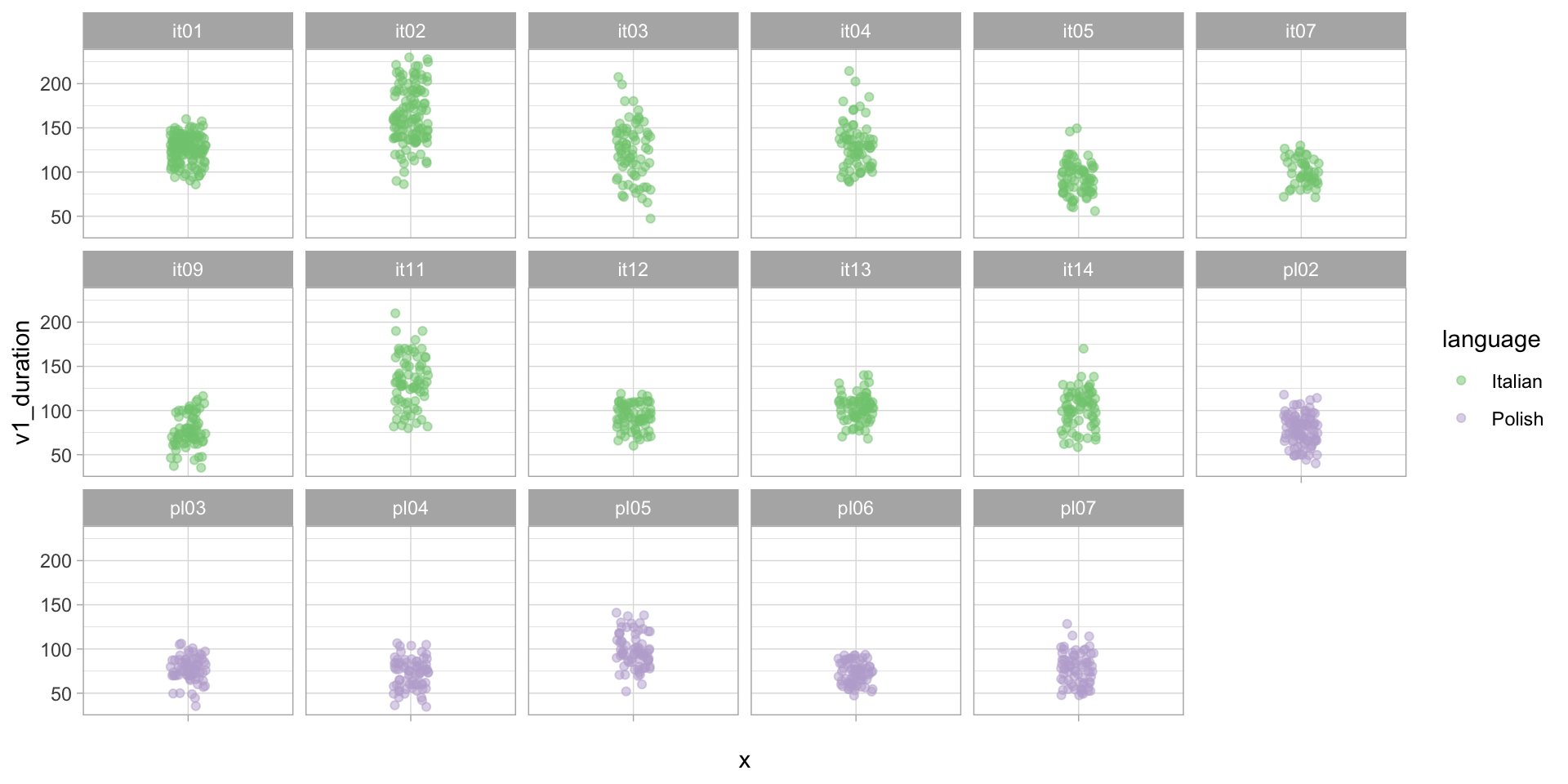
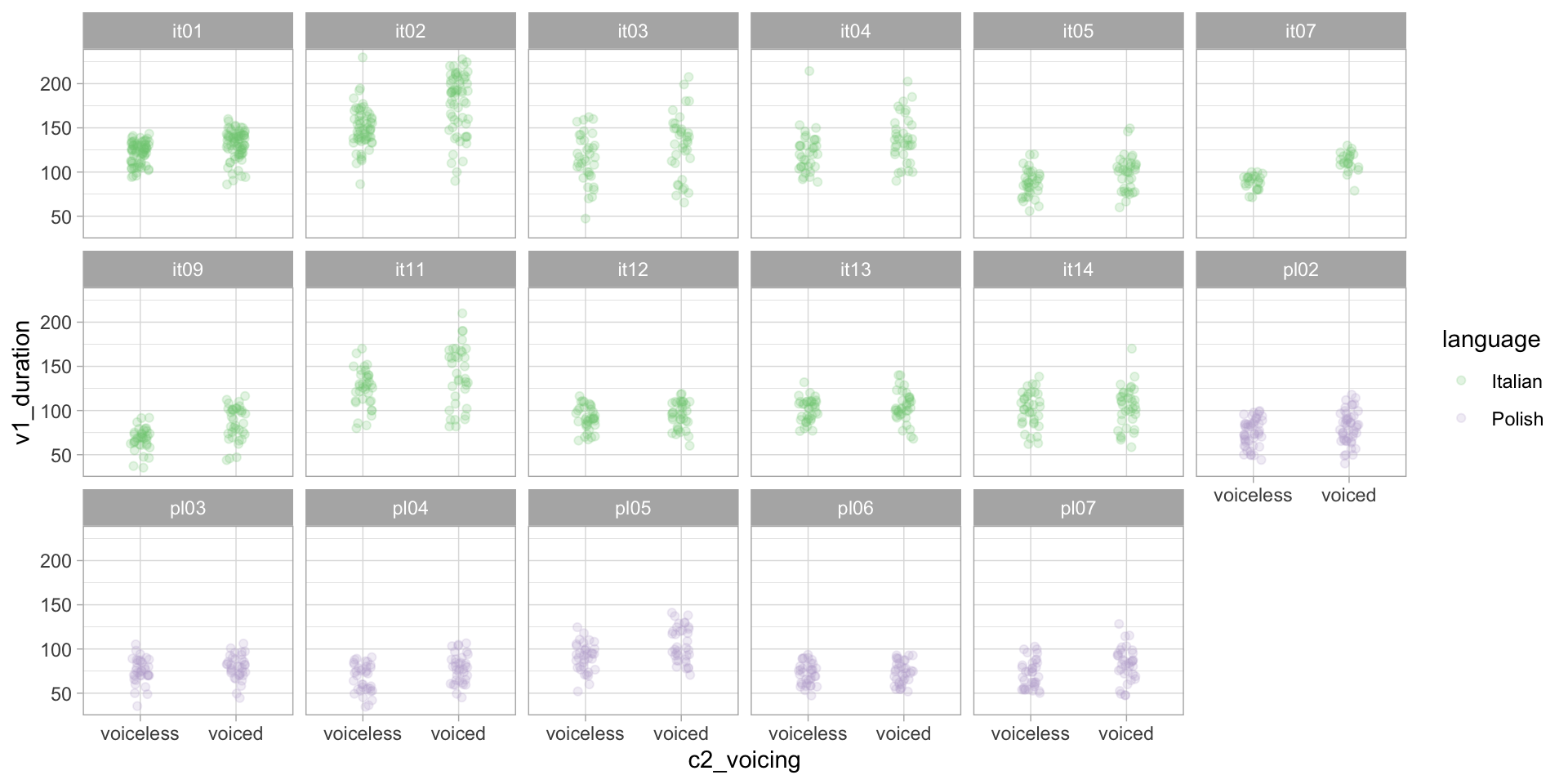
Vowel duration by speaker
Conditional predictions of vowel duration
Posterior probability distributions of effect of voicing
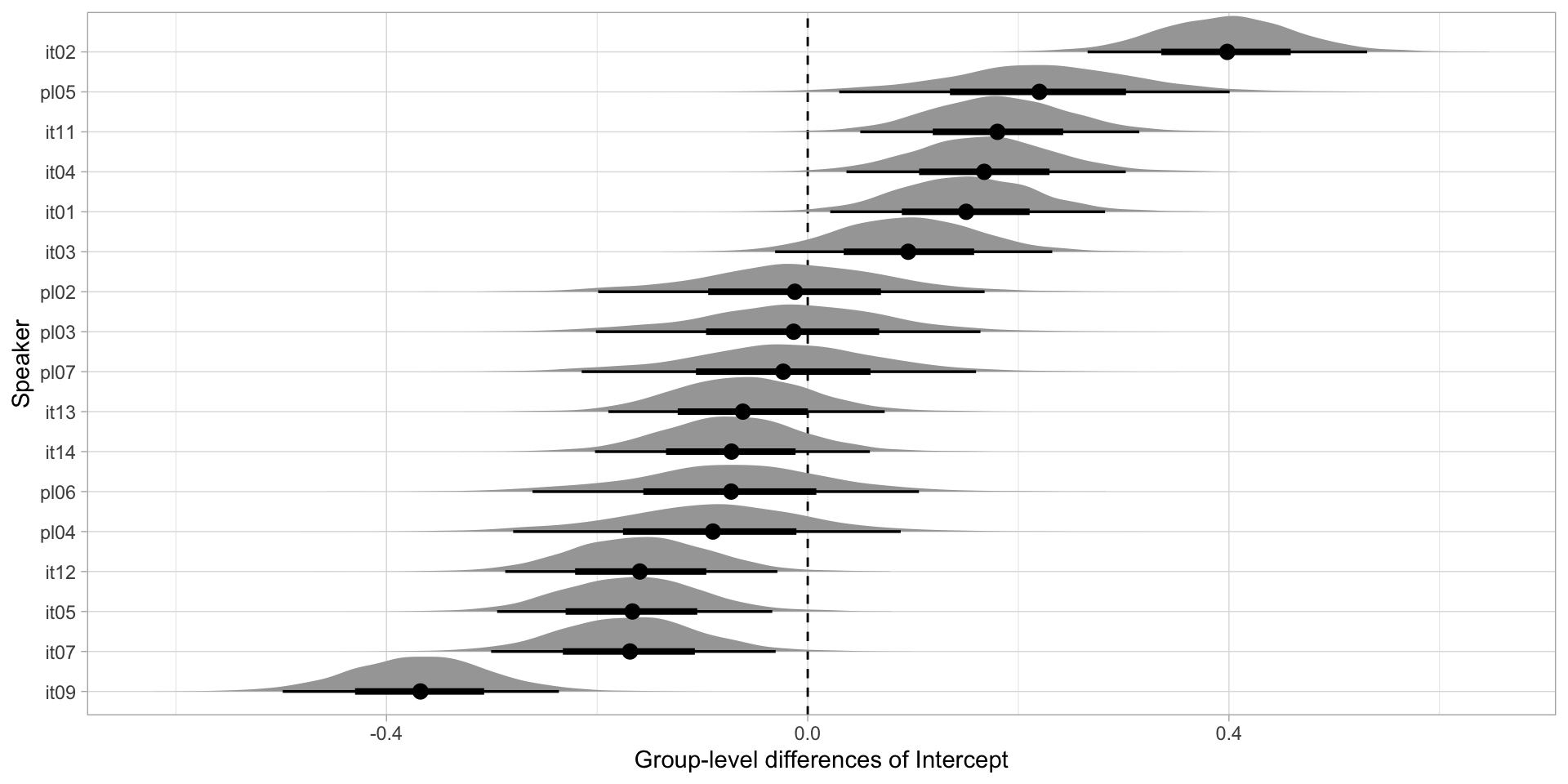
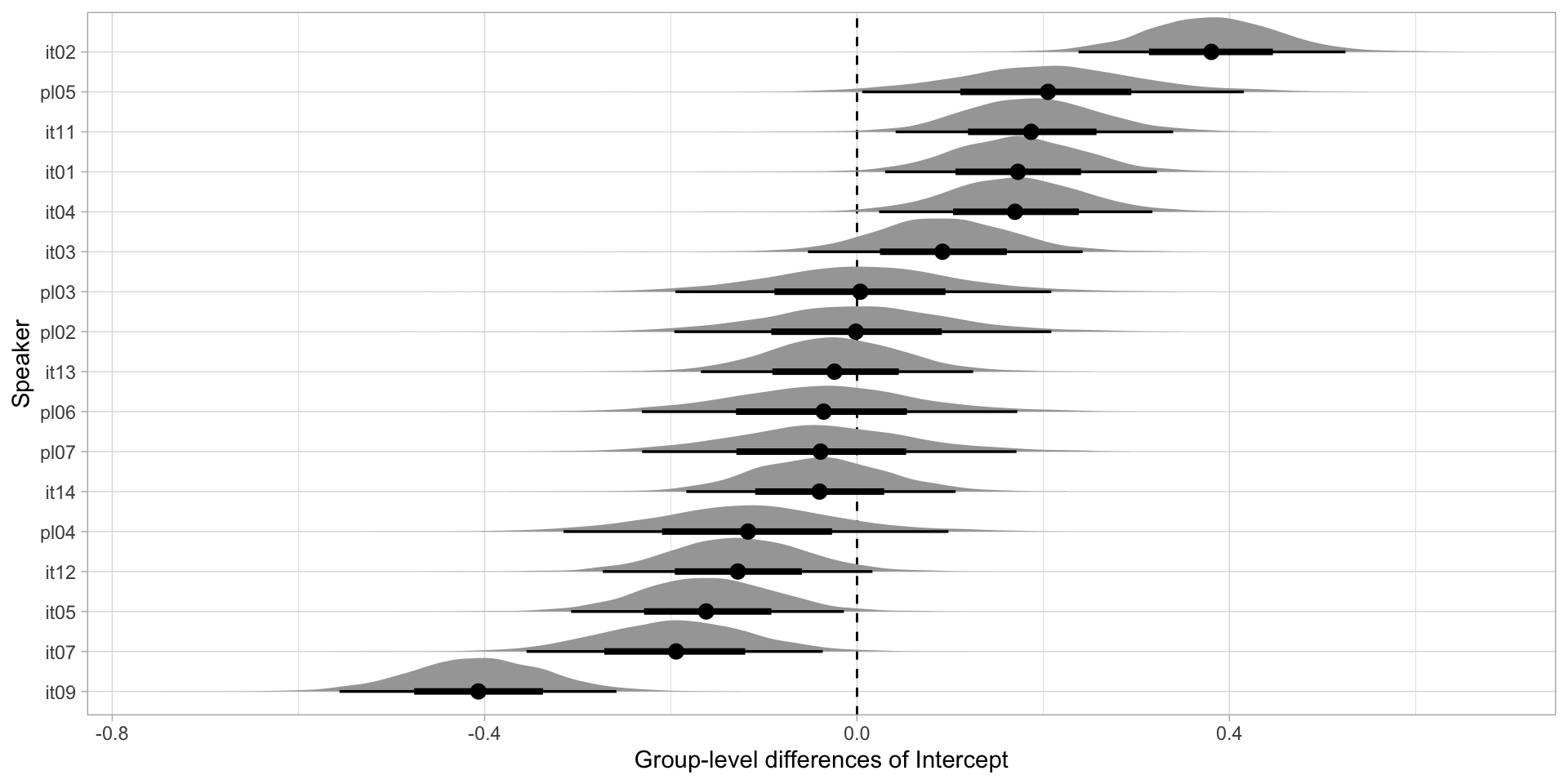
Group-level differences: Intercept
Voicing effect by speaker
Group-level differences: Intercept
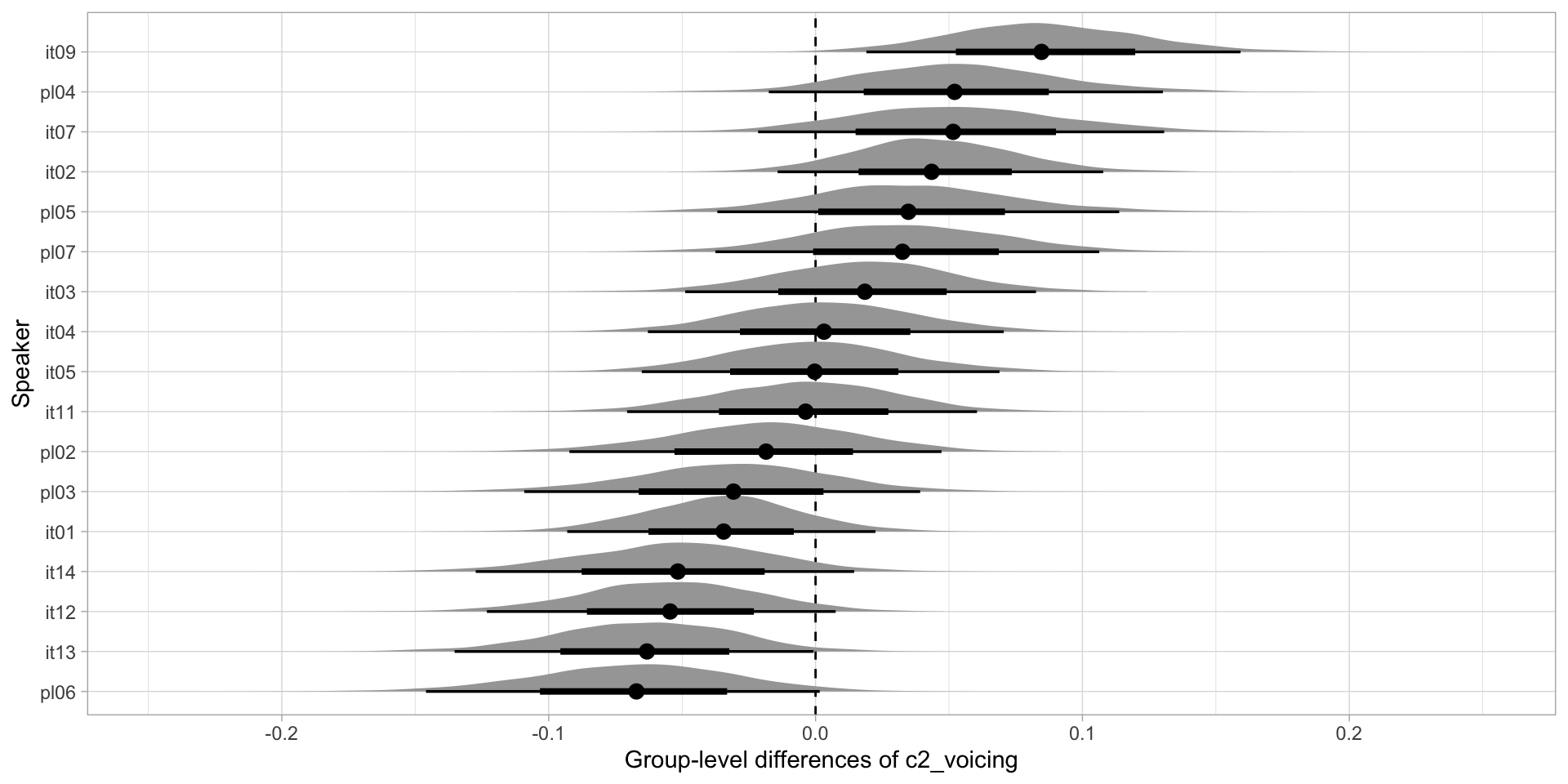
Group-level differences: c2_voicing
Conditional predictions of vowel duration
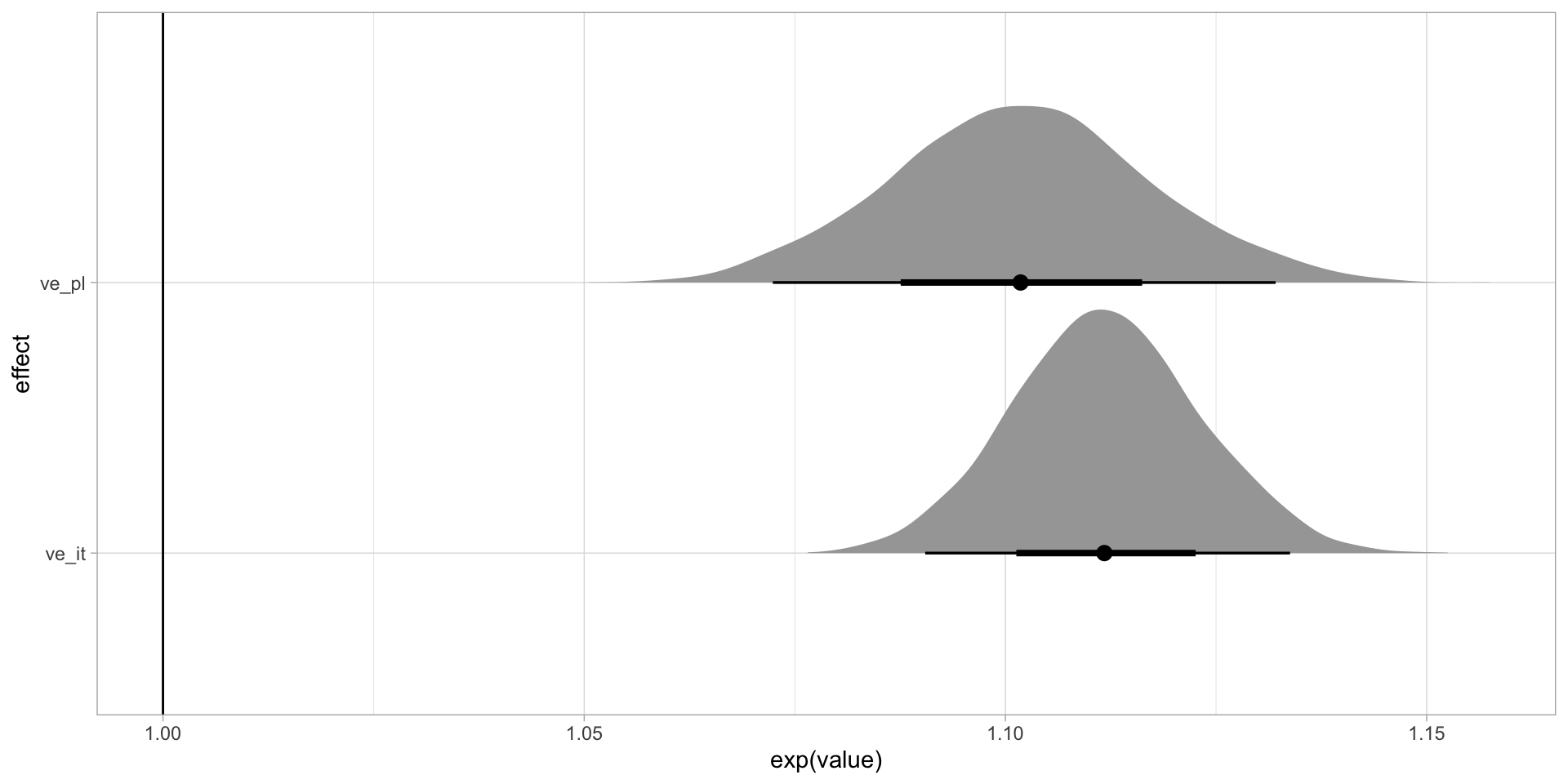
Posterior probability of voicing effect

Shrinkage