A regression model is a statistical model that estimates the relationship between an outcome variable and one or more predictor variables (more on outcome/predictor below).
Regression models are based on the formula of a straight line.
\[
y = \alpha + \beta * x
\]
1.1 Back to school
You might remember from school when you were asked to find the values of \(y\) given certain values of \(x\) and specific values of \(\alpha\) and \(\beta\).1.
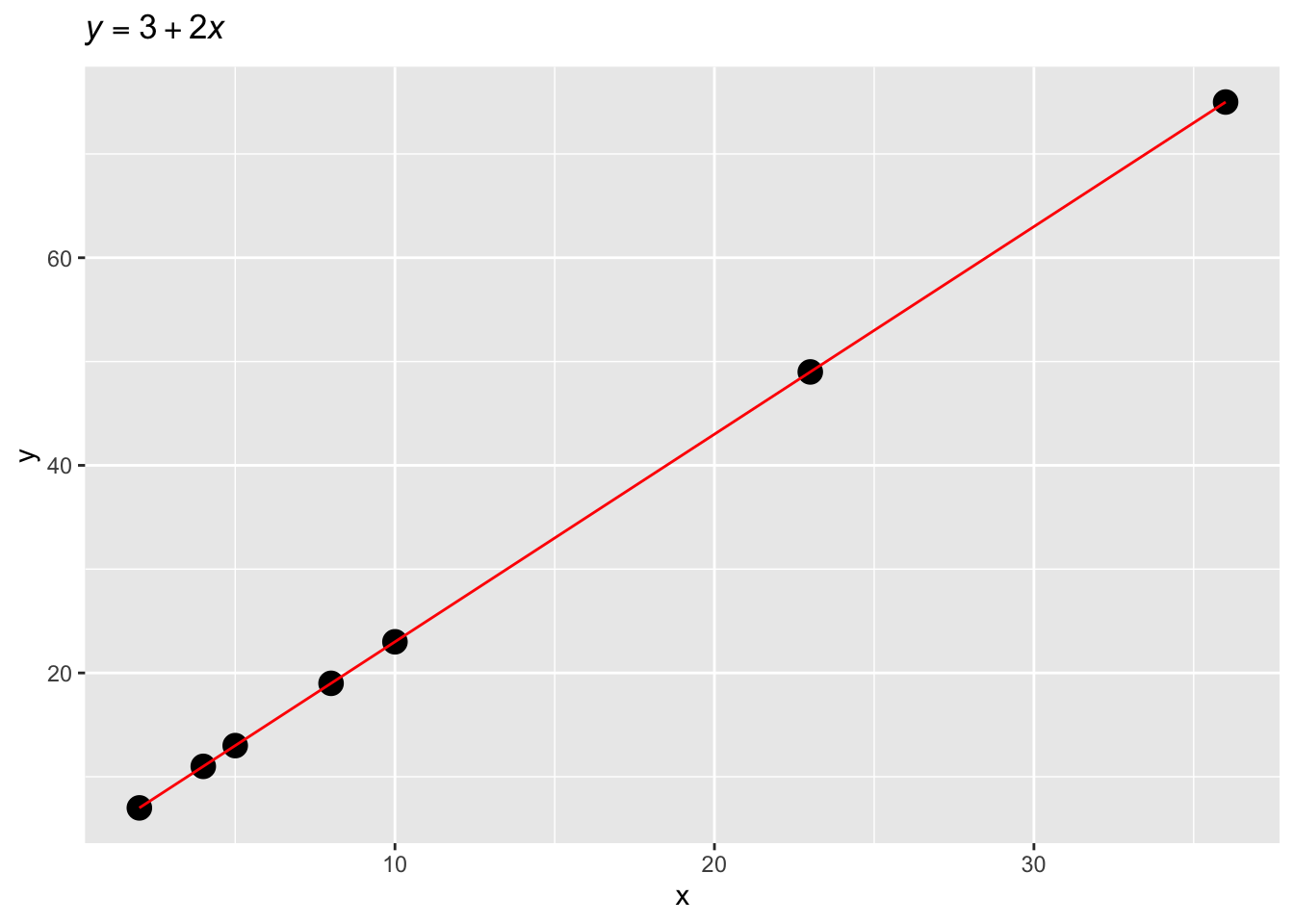
For example, you were given the following formula of a line:
\[
y = 3 + 2 * x
\]
and the values \(x = (2, 4, 5, 8, 10, 23, 36)\). The homework was to calculate the values of \(y\) and maybe plot them on a Cartesian coordinate space.
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
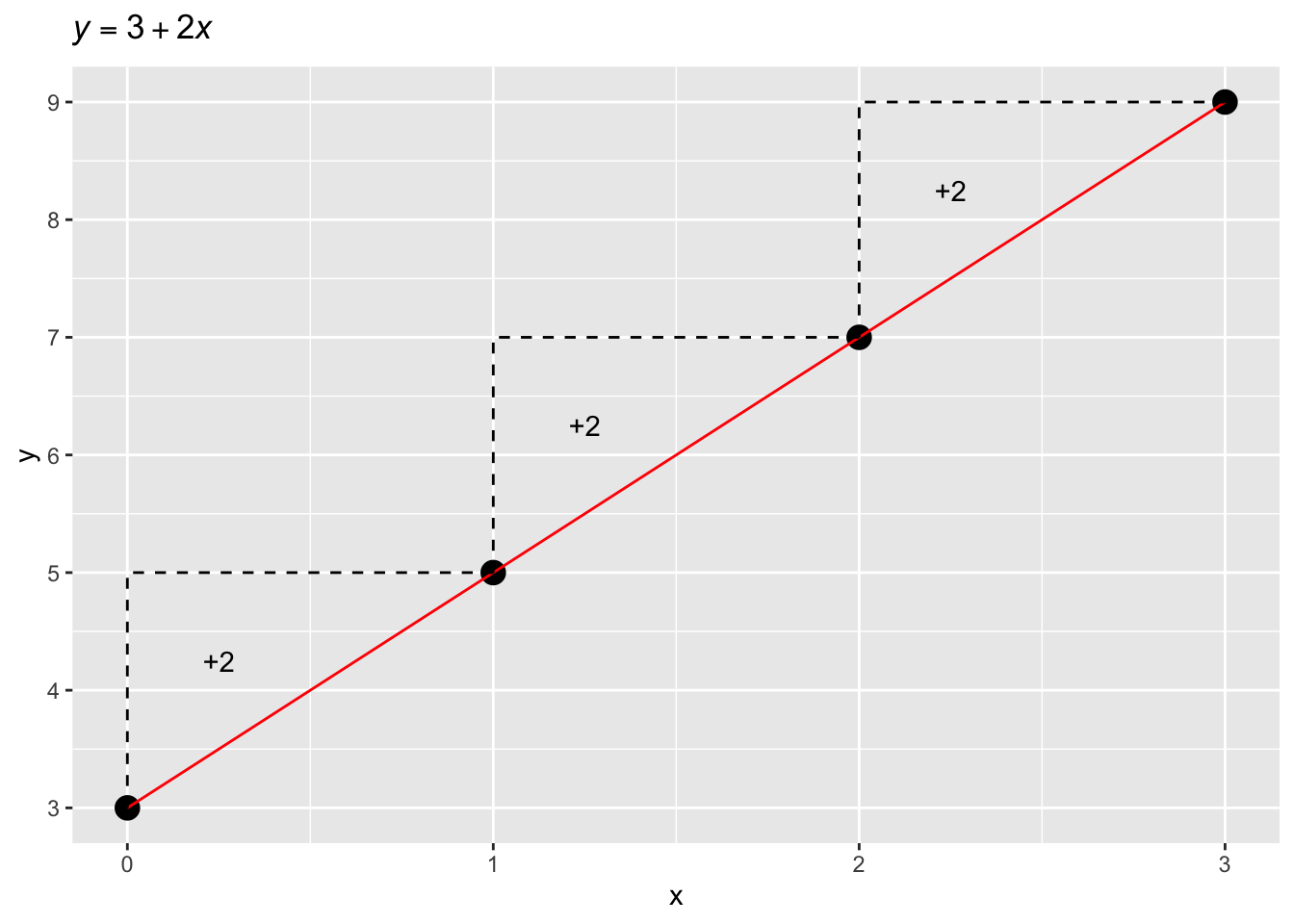
Using the formula, we are able to find the values of \(y\). Note that in \(y = 3 + 2 * x\), \(\alpha = 3\) and \(\beta = 2\). Importantly, \(\alpha\) is the value of \(y\) when \(x = 0\). \(\alpha\) is commonly called the intercept of the line.
In the plot, the dashed line indicates the increase in \(y\) for every unit increase of \(x\) (i.e., every time \(x\) increases by 1, \(y\) increases by 2).
Now, in the context of research, you usually measure \(x\) (the predictor variable) and \(y\) (the outcome variable). Then you have to estimate \(\alpha\) and \(\beta\).
This is what regression models are for: given the measured \(y\) and \(x\), the model estimates \(\alpha\) and \(\beta\).
You can play around with this web app by changing the intercept and slope of the line. Note the alternative notation:
The intercept is \(\beta_0\) rather than \(\alpha\).
The slope is \(\beta_1\) rather than \(\beta\).
Let’s use this alternative notation going forward (using \(\beta\)’s with subscript indexes will help understand the process of extracting information from regression models).
2 Add some error…
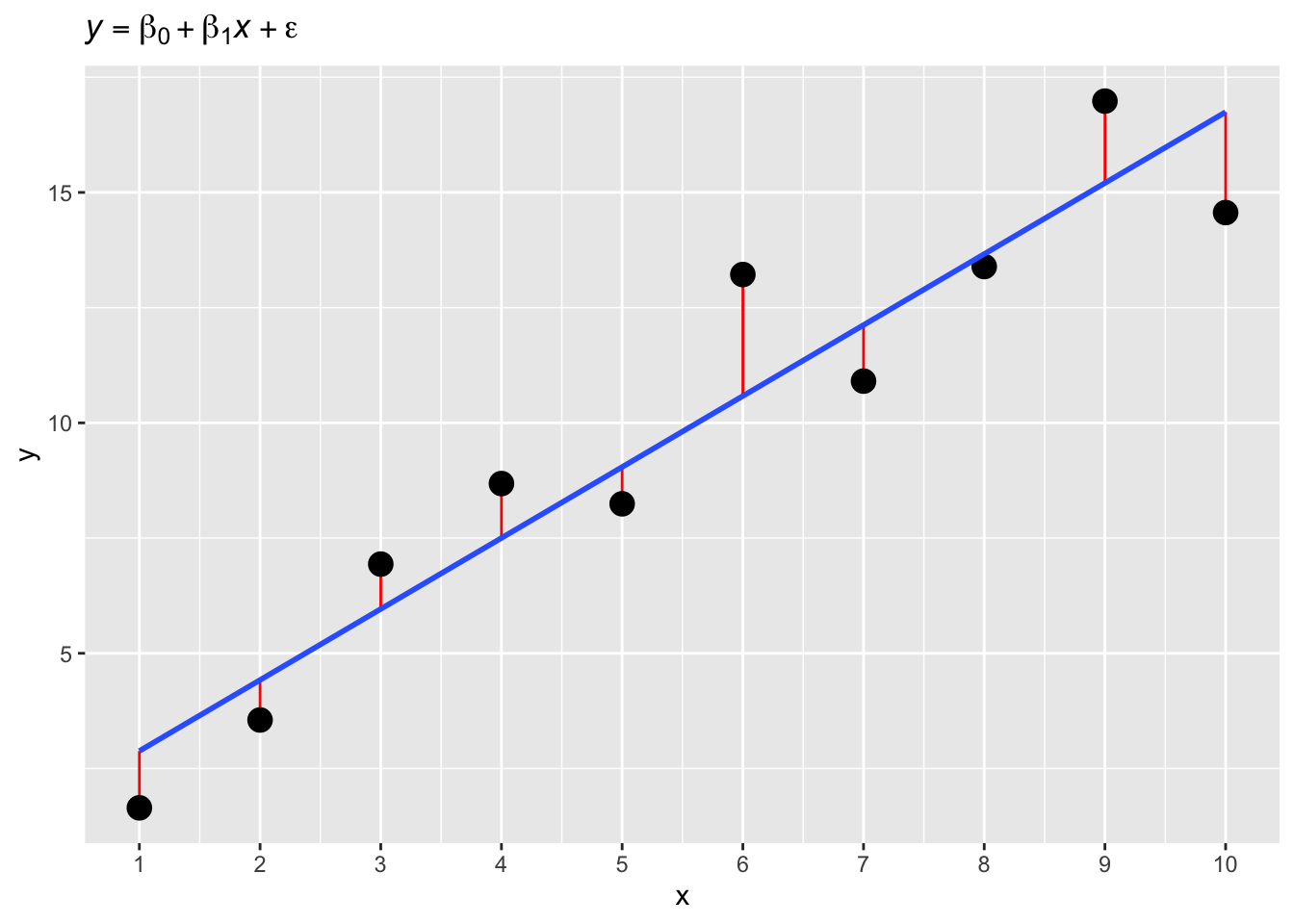
Of course, measurements are noisy: they usually contain some error. Error can have many different causes, but we are usually not interested in learning about those causes. Rather, we just want our model to be able to deal with error.
Look at the following plot. The plot shows measurements of \(x\) and \(y\). The points corresponding to the observed measurements are almost on a straight line, but not quite. The vertical distance between the observed points and the expected straight line is the residual error (red lines in the plot).
The blue line in the plot is the expected line as estimated by a regression model (you’ll learn how to run such model below), based on the \(x\) and \(y\) observations.
The formula of this regression model is the following:
\[
y = \beta_0 + \beta_1 * x + \epsilon
\]
where \(\epsilon\) is the error. In other words, \(y\) is the sum of \(\beta_0\) and \(\beta_1 * x\), plus some error.
Given that the error \(\epsilon\) is assumed to come from a distribution defined as \(Gaussian(0, \sigma)\), the formula can be rewritten by using a probability distribution (see (Introduction to regression models)[posts/intro-regression.qmd]).
Let’s get our hands dirty and model some data using a regression model.
First, let’s attach the brms package.
library(brms)
Loading required package: Rcpp
Loading 'brms' package (version 2.21.0). Useful instructions
can be found by typing help('brms'). A more detailed introduction
to the package is available through vignette('brms_overview').
Attaching package: 'brms'
The following object is masked from 'package:stats':
ar
We will analyse the duration of vowels in Italian.
3.1 Vowel duration in Italian
Let’s read the R data file coretta2018a/ita_egg.rda. It contains several phonetic measurements obtained from audio and electroglottographic recordings.
In this tutorial, we will model vowel duration as a function of speech rate (i.e. number of syllables per second).
The expectation is that vowels get shorter with increasing speech rate. You will notice how this is a very vague hypothesis: how shorter do they get? is the shortening the same across all speech rates, or does it get weaker with high speech rates? Our expectation/hypothesis simply states that vowels get shorter with increasing speech rate.
Maybe we could do better and use what we know from speech production and come up with something more precise, but these type of vague hypothesis are very common, if not standard, in language research, so we will stick to it for practical and pedagogical reasons.
Here’s the data
load("data/coretta2018a/ita_egg.rda")ita_egg
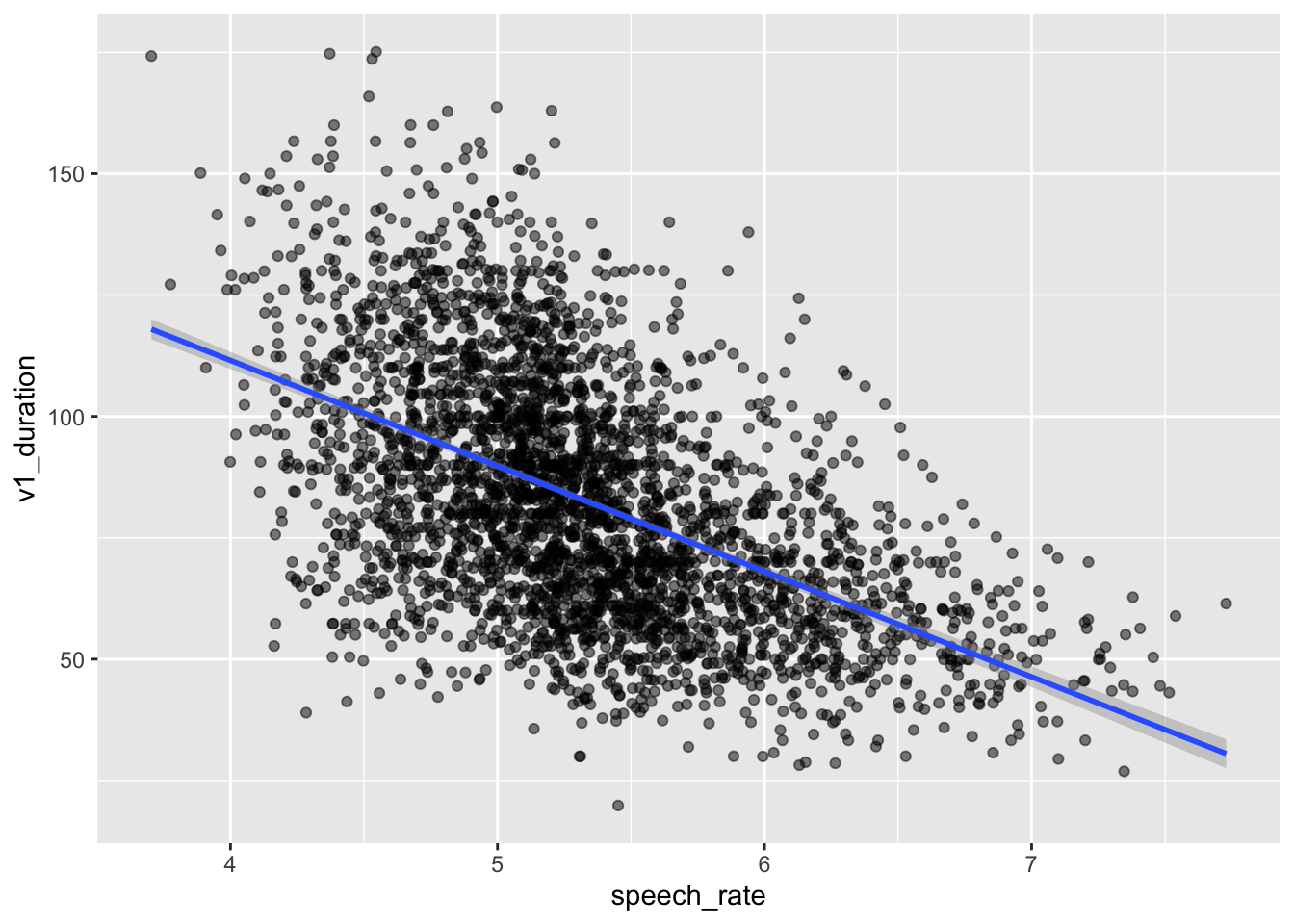
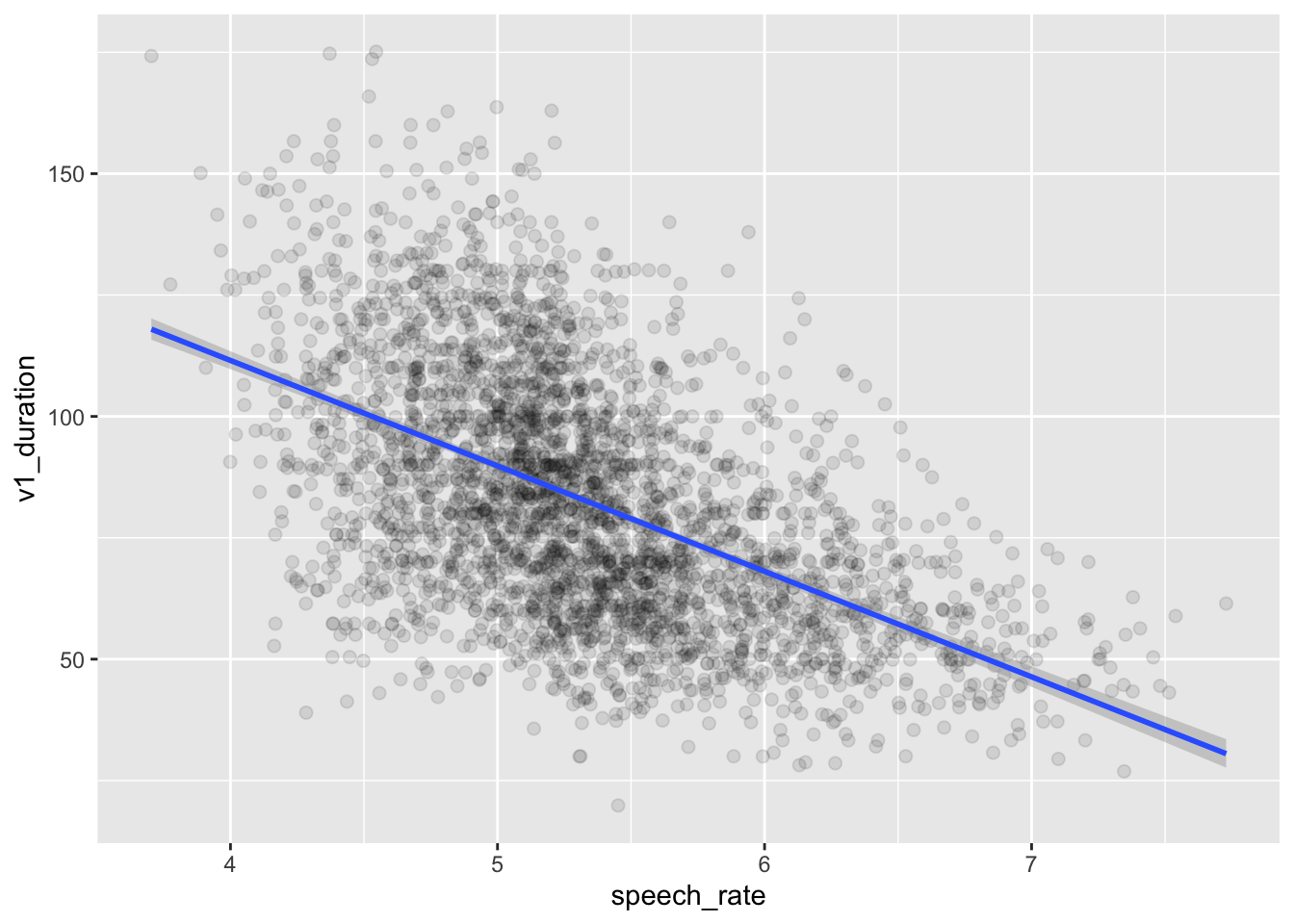
Let’s plot vowel duration and speech rate in a scatter plot.
Warning: Removed 15 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 15 rows containing missing values or values outside the scale range
(`geom_point()`).
By glancing at the raw data, we see a negative relationship between speech rate and vowel duration: vowels get shorter with greater speech rate.
You might have noticed a warning about missing values. This is because some observations actually are missing (NA). Let’s drop them from the tibble with drop_na().
ita_egg_clean <- ita_egg |>drop_na(v1_duration)
We will use ita_egg_clean for the rest of the tutorial.
Before that though, create a folder called cache/ in the data/ folder of the RStudio project of the course. We will use this folder to save the output of model fitting so that you don’t have to refit the model every time. This is useful because as models get more and more complex, they can take quite a while to fit.
The model will be fitted and saved in cache/ with the file name vow_bm.rds. If you now re-run the same code again, you will notice that brm() does not fit the model again, but rather reads it from the file (no output is shown, but trust me, it works! Check the contents of cache/ to see for yourself.).
Warning
When you save the model fit to a file, R does not keep track of changes in the model specification, so if you make changes to the formula or data, you need to delete the saved model file before re-running the code for the changes to have effect!
4 Interpret the model summary
To obtain a summary of the model, use the summary() function.
summary(vow_bm)
Family: gaussian
Links: mu = identity; sigma = identity
Formula: v1_duration ~ speech_rate
Data: ita_egg_clean (Number of observations: 3253)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
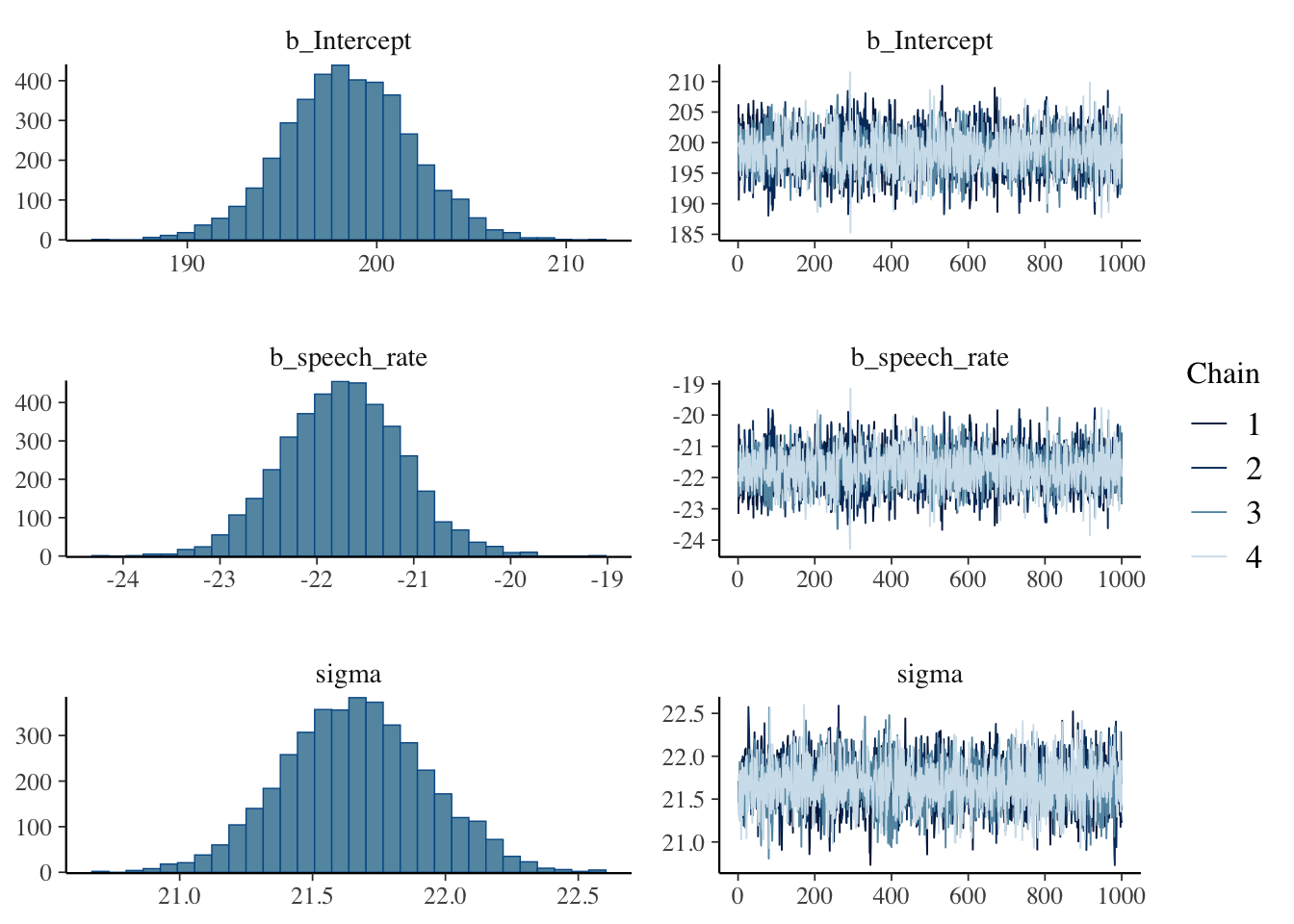
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 198.47 3.33 191.76 204.97 1.00 3681 2274
speech_rate -21.73 0.62 -22.93 -20.49 1.00 3623 2421
Further Distributional Parameters:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
sigma 21.66 0.27 21.14 22.19 1.00 3855 2615
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
Let’s focus on the “Regression Coefficients” table of the summary. To understand what they are, just remember the equation of line and the model formula above.
Intercept is \(\beta_0\): this is the mean vowel duration, when speech rate is 0.
speech_rate is \(\beta_1\): this is the change in vowel duration for each unit increase of speech rate.
This should make sense, if you understand the equation of a line: \(y = \beta_0 + \beta_1 x\). If you are still uncertain, play around with the web app.
Recall that the Estimate and Est.Error column are simply the mean and standard deviation of the posterior probability distributions of the estimate of Intercept and speech_rate respectively.
Looking at the 95% Credible Intervals (CrIs), we can say that based on the model and data:
The mean vowel duration, when speech rate is 0 syl/s, is between 192 and 205 ms, at 95% confidence.
We can be 95% confident that, for each unit increase of speech rate (i.e. for each increase of one syllable per second), the duration of the vowel decreases by 20.5-23 ms.
To see what the posterior probability densities of \beta_0, \beta_1 and \sigma look like, you can quickly plot them with the plot() function.
plot(vow_bm)
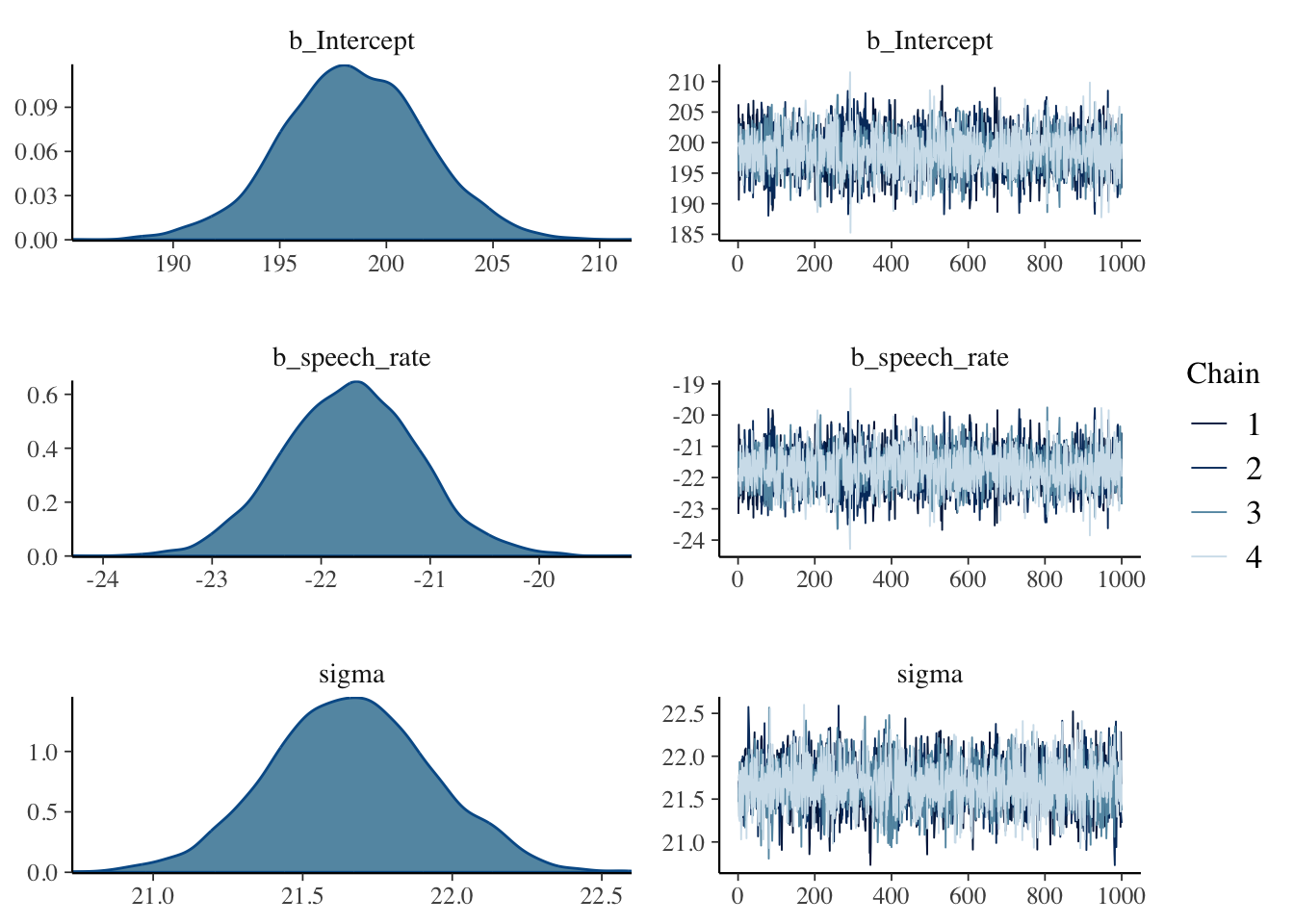
If you prefer to see density plots instead of histograms, you can specify the combo argument.
plot(vow_bm, combo =c("dens", "trace"))
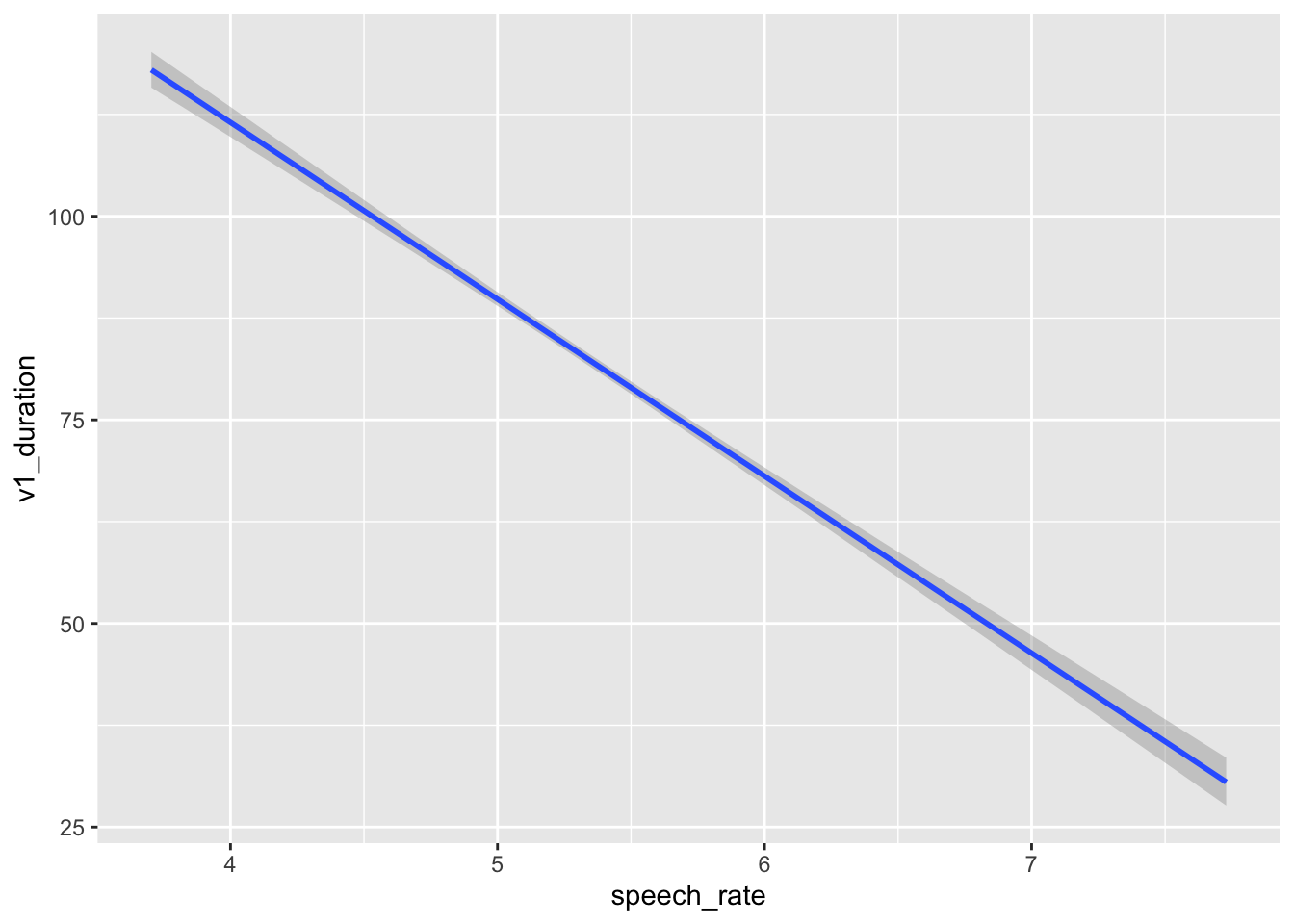
5 Plot the model predictions
You should always also plot the model predictions, i.e. the predicted values of vowel duration based on the model predictors (here just speech_rate).
You will learn more advanced methods later on, but for now you can use conditional_effects() from the brms package.
If you wish to include the raw data in the plot, you can wrap conditional_effects() in plot() and specify points = TRUE. Any argument that needs to be passed to geom_point() (these are all ggplot2 plots!) can be specified in a list as the argument point_args. Here we are making the points transparent.
Depending on which country you did your schooling in, you might be used to slightly different notation, like \(mx + c\). In \(mx + c\), \(m\) is \(\beta\) and \(c\) is \(\alpha\).↩︎