Bayesian regression models fitted with brms/Stan use the Markov Chain Monte Carlo (MCMC) sampling algorithm to estimate the probability distributions of the model’s coefficient.
You have encountered MCMC algorithm in Introduction to regression. What the MCMC algorithm does is to sample values (draws) from the posterior distribution to reconstruct it (to learn more about this, see Finding posteriors through sampling by Elizabeth Pankratz and resources therein).
When you run a model with brms, those sampled values (draws) are stored in the model object. Virtually all operations on model are actually done with those draws.
We normally fit BRMs with four MCMC chain. The sampling algorithm within each chain runs for 2000 iterations by default. The first half (1000 iterations) are used to “warm up” the algorithm (i.e. optimise a few parameters of the algorithm) while the second half (1000 iterations) are the ones to reconstruct the posterior distribution.
For four chains ran with 2000 iterations of which 1000 for warm up, we end up with 4000 iterations we can use to learn details about the posteriors.
The rest of the post will teach you how to extract and manipulate the model’s draws.
2 Extract MCMC posterior draws
Let’s read the winter2012/polite.csv data again first.
Rows: 224 Columns: 27
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (6): subject, gender, birthplace, musicstudent, task, attitude
dbl (21): months_ger, scenario, total_duration, articulation_rate, f0mn, f0s...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
polite
Now we can reload the Bayesian regression model from Introduction to regression models (Part II). We simply use the same code: but now, instead of the model being fit again, the code will just read the file cache/hnr_bm.rds.
It’s always good to inspect the summary to make sure the model is the correct one.
summary(hnr_bm, prob =0.8)
Family: gaussian
Links: mu = identity; sigma = identity
Formula: HNRmn ~ attitude
Data: polite (Number of observations: 224)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-80% CI u-80% CI Rhat Bulk_ESS Tail_ESS
Intercept 16.28 0.15 16.08 16.47 1.00 4239 2929
attitudepol 1.25 0.22 0.96 1.54 1.00 3854 2983
Further Distributional Parameters:
Estimate Est.Error l-80% CI u-80% CI Rhat Bulk_ESS Tail_ESS
sigma 1.69 0.08 1.59 1.79 1.00 3898 2885
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
The Regression Coefficients table includes Intercept and attitudepoliteite which is what we expect from the model formula and data. We are good to go!
Now we can extract the MCMC draws from the model using the as_draws_df() function.
This function returns a tibble with values obtained at each draw of the MCMC draws. Since we fitted the model with 4 chains and 1000 sampling draws per chain, there is a total of 4000 drawn values (i.e. 4000 rows).
hnr_bm_draws <-as_draws_df(hnr_bm)hnr_bm_draws
Don’t worry about the lprior and lp__ columns. The columns .chain, .iteration and .draw indicate:
The chain number (1 to 4).
The iteration number within chain (1 to 1000).
The draw number across all chains (1 to 4000).
The following columns contain the drawn values at each draw for three parameters of the model: b_Intercept, b_attitude and sigma. To remind yourself what these mean, let’s have a look at the mathematical formula of the model.
b_Intercept is \(\beta_0\). This is the mean HNR when the attitude is informal.
b_attitudepolite is \(\beta_1\). This is the difference in HNR between polite and informal attitude.
sigma is \(\sigma\). This is the overall standard deviation.
3 Summaries and plotting of posterior draws
The Regression Coefficients table reports summaries of the distribution of the drawn values of b_Intercept and b_attitudepolite. These summary measures are the mean (Estimate), the standard deviation (Est.error) and the lower and upper limits of the credible interval.
We can of course obtain those same measures ourselves from the draws tibble!
library(posterior)
This is posterior version 1.6.0
Attaching package: 'posterior'
The following objects are masked from 'package:stats':
mad, sd, var
The following objects are masked from 'package:base':
%in%, match
Warning: Dropping 'draws_df' class as required metadata was removed.
Hopefully now it is clear where the values in the Regression Coefficient table come from and how these are related to the MCMC draws.
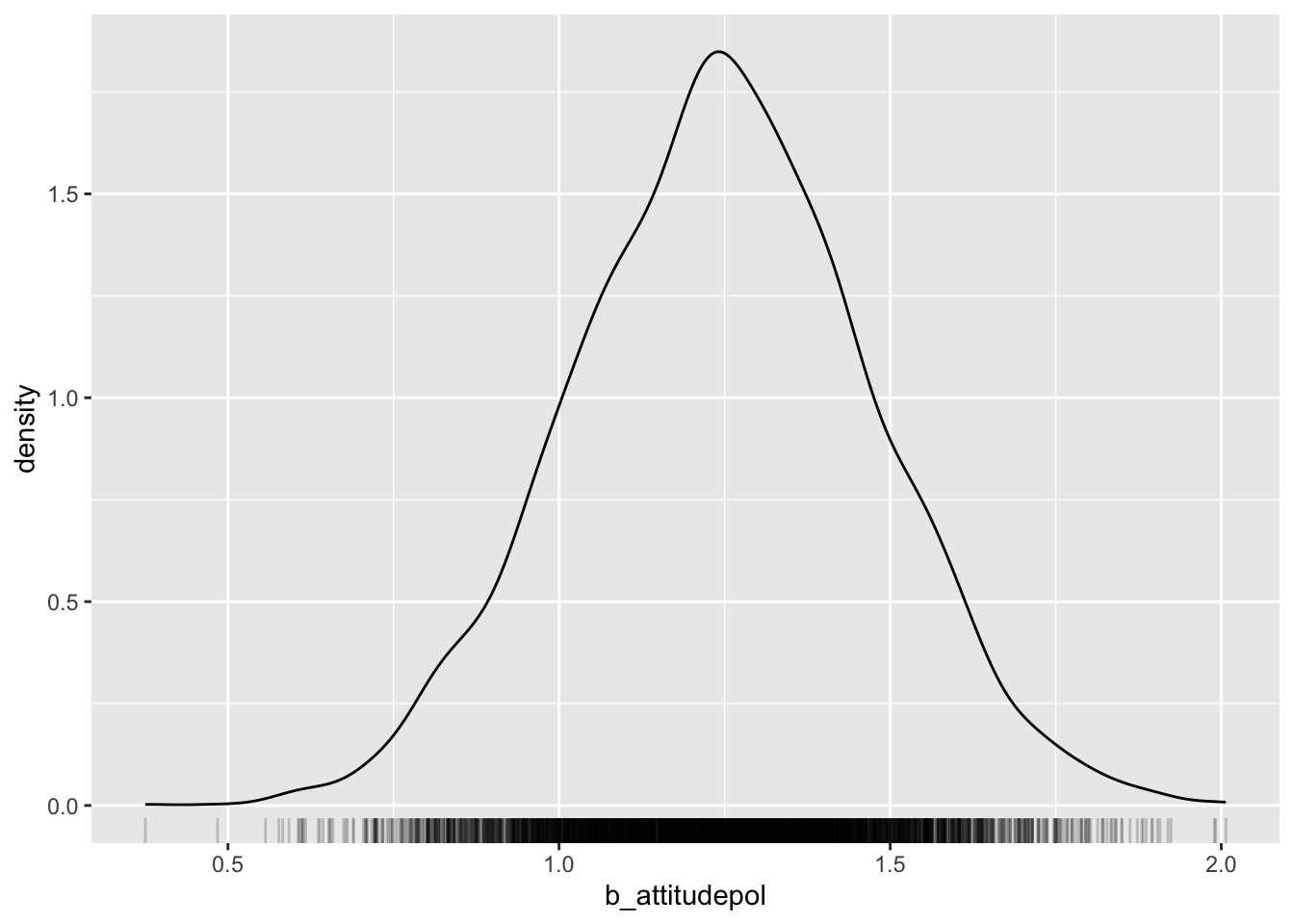
Next we can plot the (posterior) probability distribution of the draws for any parameter. Let’s plot b_attitudepolite. This will be the posterior probability density of the difference in HNR between the polite and informal attitude.
When is_polite is 0, attitude is informal and we have \(\mu = \beta_0\). When is_polite is 1, attitude is polite and we have \(\mu = \beta_0 + \beta_1\).
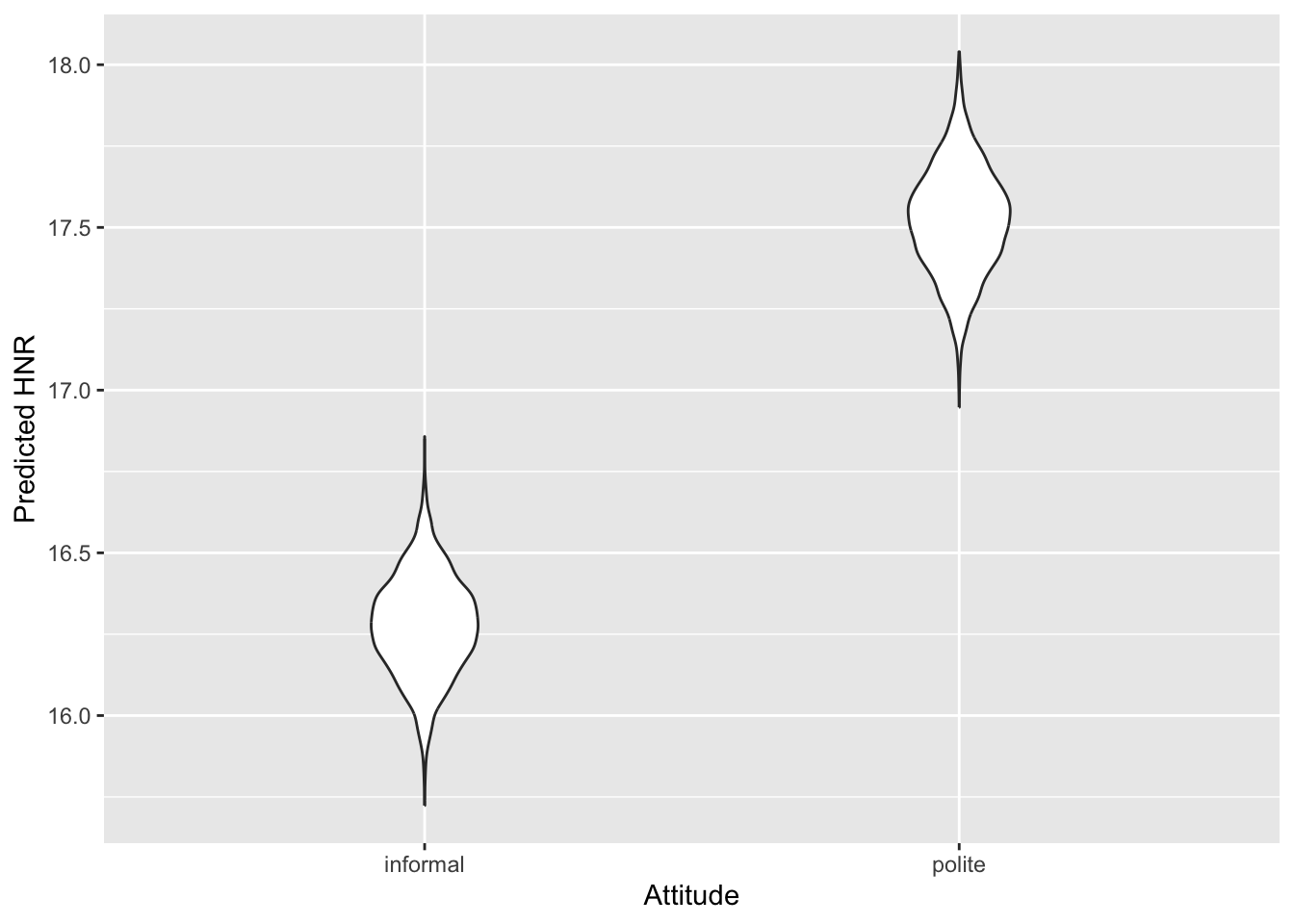
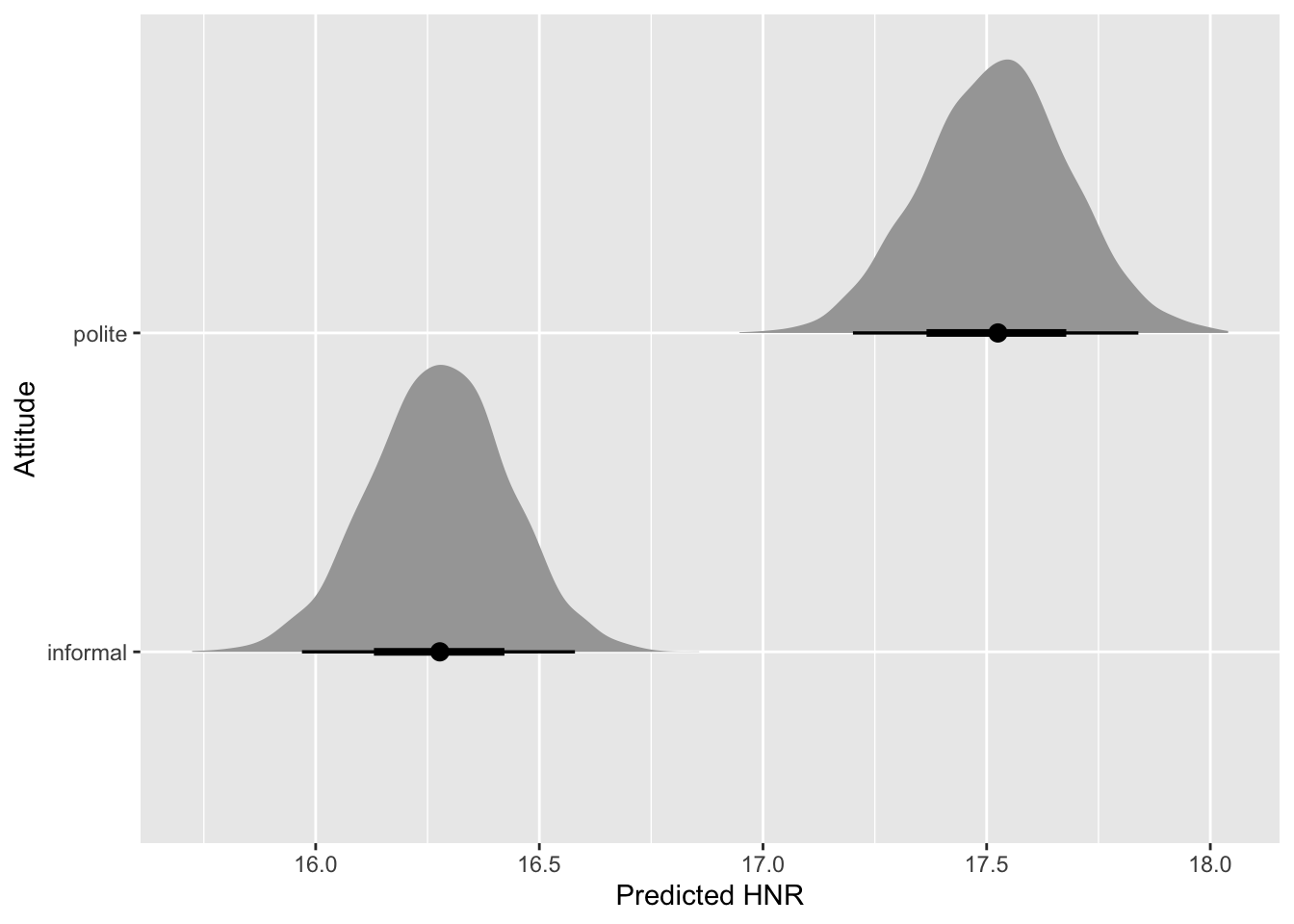
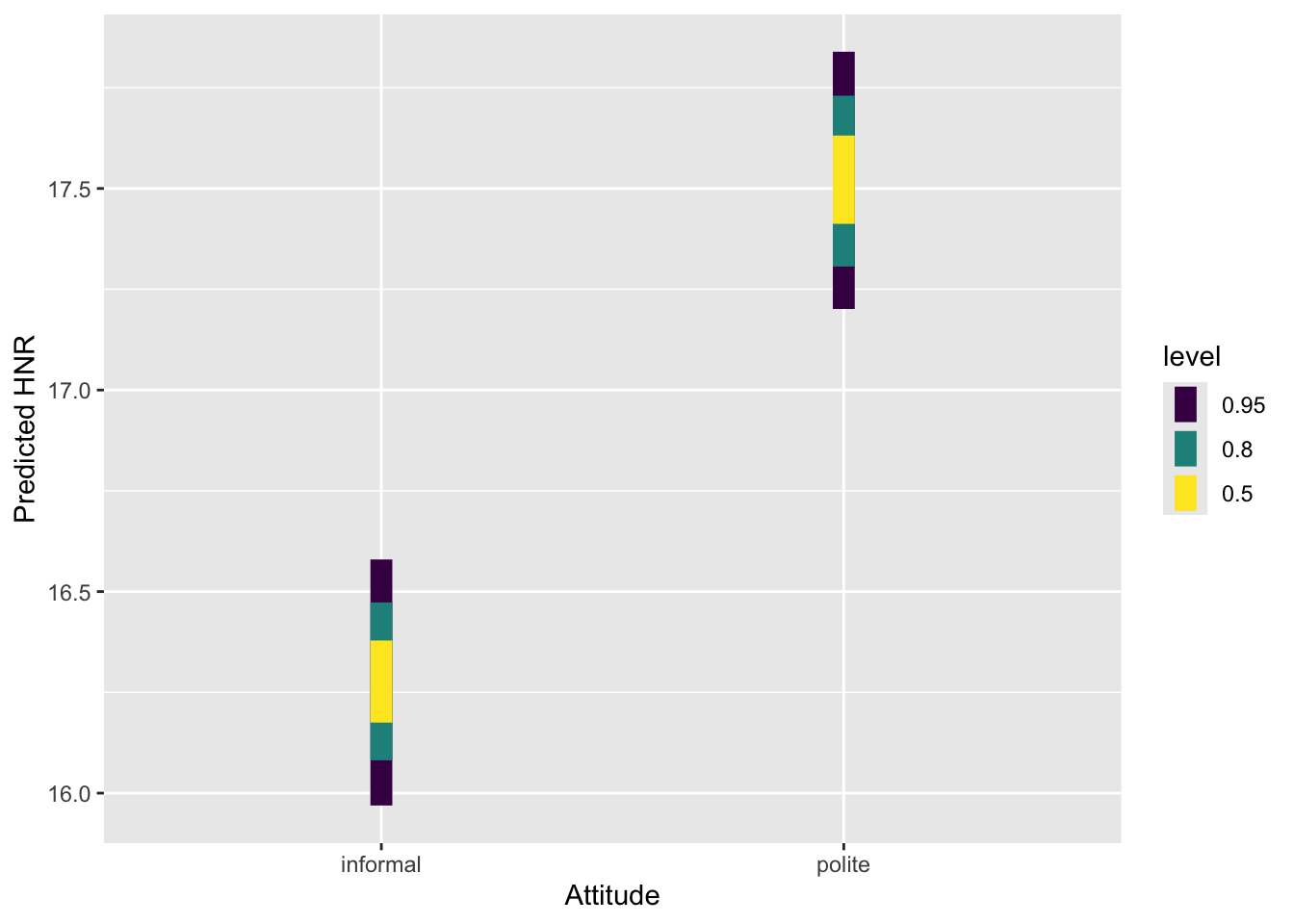
So, to get the predicted HNR when attitude is polite, we just need to sum b_Intercept (\(\beta_0\)) and b_attitudepolite (\(\beta_1\)).
The sum operation is applied row-wise, to each draw. So, for polite, the value of b_Intercept at draw 1 is added to the value of b_attitudepolite at draw 1, and so on. You end up with a list of sums that has the same length as the initial draws (here, 4000, i.e. 1000 per chain!). Then you can summarise and plot this new list as you did with the b_ coefficients.
According to the model, the predicted HNR when attitude is informal is between 16 and 16.48 at 80% confidence (\(\beta\) = 16.27, SD = 0.16). When attitude is polite, the predicted HNR is between 17.31 and 17.73 (\(\beta\) = 17.53, SD = 0.16).