Learn how to change the format of data tables from long to wide and viceversa using the pivot functions from tidyr
Author
Stefano Coretta
Published
July 15, 2024
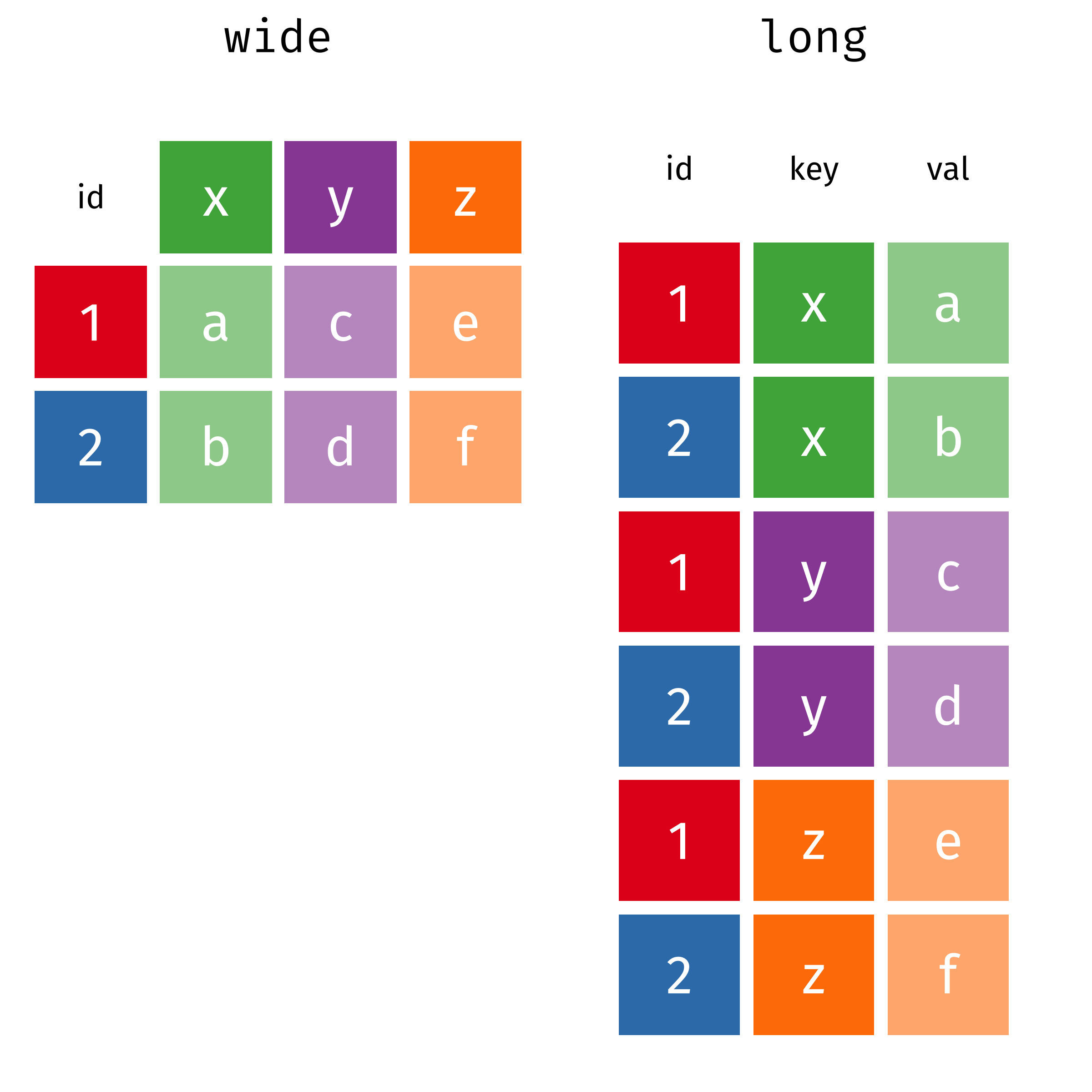
1 Pivoting
Pivoting is the process of changing the shape of the data from a long format to a wide format and vice versa. You can find nice animations on Garrick’s website that illustrate the process.
Ch 5 of the R4DS book introduces the concept of long and wide formats and teaches you how to pivot data using the pivot_wider() and pivot_longer() functions from tidyr (a tidyverse package).
Make sure you try the code out yourself and feel free to try the exercises as well (you can find the solutions here).
You can practice with the coretta2018/ultrasound/ data which includes a set of files with data from ultrasound tongue imaging of Italian and Polish speakers.
files <-list.files("data/coretta2018/ultrasound",full.names =TRUE,pattern ="*-tongue-cart.tsv")# Column names of the first 14 columns. The rest of the columns are X and Y# coordinates of tongue contours of 42 points along the contour:# X1,Y1,X2,Y2,X3,Y3,...,X42,Y42.## Note that R automatically names unnamed columns with X followed by# the column number, so the 84 coordinate columns will be all named Xn.columns <-c("speaker","seconds","rec_date","prompt","label","TT_displacement_sm","TT_velocity","TT_velocity_abs","TD_displacement_sm","TD_velocity","TD_velocity_abs","TR_displacement_sm","TR_velocity","TR_velocity_abs")tongue <-read_tsv(files, id ="file", col_names = columns, na ="*")
Warning: One or more parsing issues, call `problems()` on your data frame for details,
e.g.:
dat <- vroom(...)
problems(dat)
Rows: 7598 Columns: 99
── Column specification ────────────────────────────────────────────────────────
Delimiter: "\t"
chr (4): speaker, rec_date, prompt, label
dbl (94): seconds, TT_displacement_sm, TT_velocity, TT_velocity_abs, TD_disp...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.