Here you will learn how to include interactions between categorical predictors and how to interpret the output. Relative to categorical-numeric interactions, categorical-categorical interactions are easier to interpret: you basically just get a coefficient for each combination of each level in the two categorical predictors and all of these coefficients can be though of as intercepts.
Rows: 6500 Columns: 11
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): Group, ID, List, Target, Critical_Filler, Word_Nonword, Relation_ty...
dbl (3): ACC, RT, logRT
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
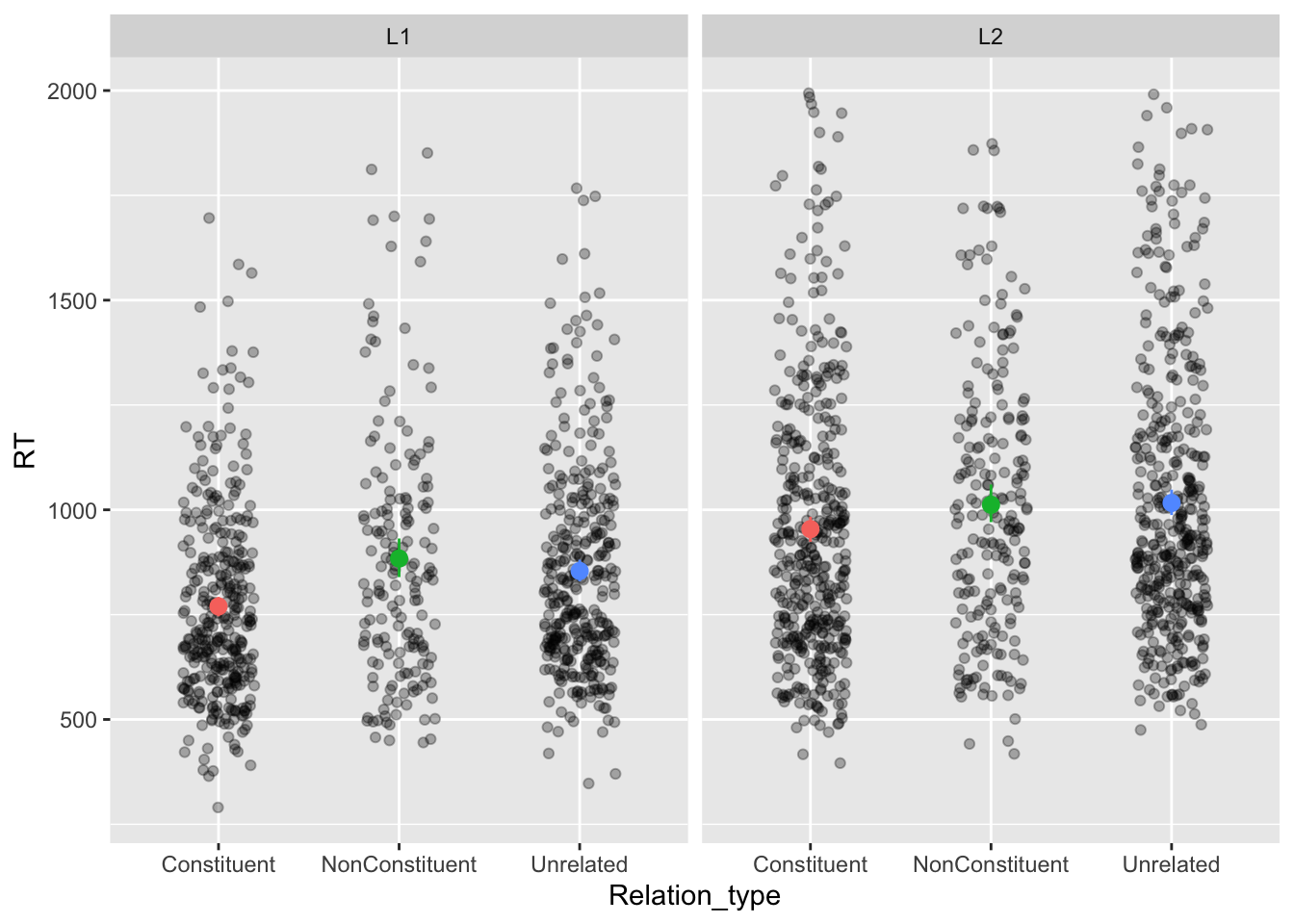
We will be looking at RTs and relation type in L1 and L2 participants. Let’s plot the RTs.
The means marked by coloured points in the plot suggest there might be a smaller difference in RTs between constituent and non-constituent/unrelated in the L2 than in the L1 group.
An interesting question we can ask is how much smaller is the difference in the L1 group compared to the L2 group. We can fit a regression model and wrangle the posterior draws to answer that question.
3 The model
We want to allow the model to estimate mean RTs for each combination of relation type (Relation_type) and group (Group). Both predictors are categorical. We can achieve this by including an interaction term between the two categorical predictors: Relation_type:Group.
When both predictors are categorical, you only need the interaction term when suppressing the intercept with 0 +. The model will estimate a coefficient for each combination of levels in the two predictors.
Check out the summary of the model. You will find 6 regression coefficients: 3 relation types (Constituent, Non-constituent, Unrelated) * 2 groups (L1 and L2).
summary(shallow_bm, prob =0.8)
Family: gaussian
Links: mu = identity; sigma = identity
Formula: logRT ~ 0 + Relation_type:Group
Data: shallow (Number of observations: 1920)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Regression Coefficients:
Estimate Est.Error l-80% CI u-80% CI Rhat
Relation_typeConstituent:GroupL1 6.60 0.02 6.58 6.63 1.00
Relation_typeNonConstituent:GroupL1 6.73 0.02 6.70 6.76 1.00
Relation_typeUnrelated:GroupL1 6.71 0.02 6.69 6.73 1.00
Relation_typeConstituent:GroupL2 6.81 0.02 6.79 6.83 1.00
Relation_typeNonConstituent:GroupL2 6.87 0.02 6.84 6.90 1.00
Relation_typeUnrelated:GroupL2 6.88 0.01 6.86 6.90 1.00
Bulk_ESS Tail_ESS
Relation_typeConstituent:GroupL1 5737 3141
Relation_typeNonConstituent:GroupL1 5664 3306
Relation_typeUnrelated:GroupL1 5700 2801
Relation_typeConstituent:GroupL2 5314 2445
Relation_typeNonConstituent:GroupL2 6533 2703
Relation_typeUnrelated:GroupL2 5573 3056
Further Distributional Parameters:
Estimate Est.Error l-80% CI u-80% CI Rhat Bulk_ESS Tail_ESS
sigma 0.31 0.01 0.30 0.31 1.00 5850 3101
Draws were sampled using sampling(NUTS). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
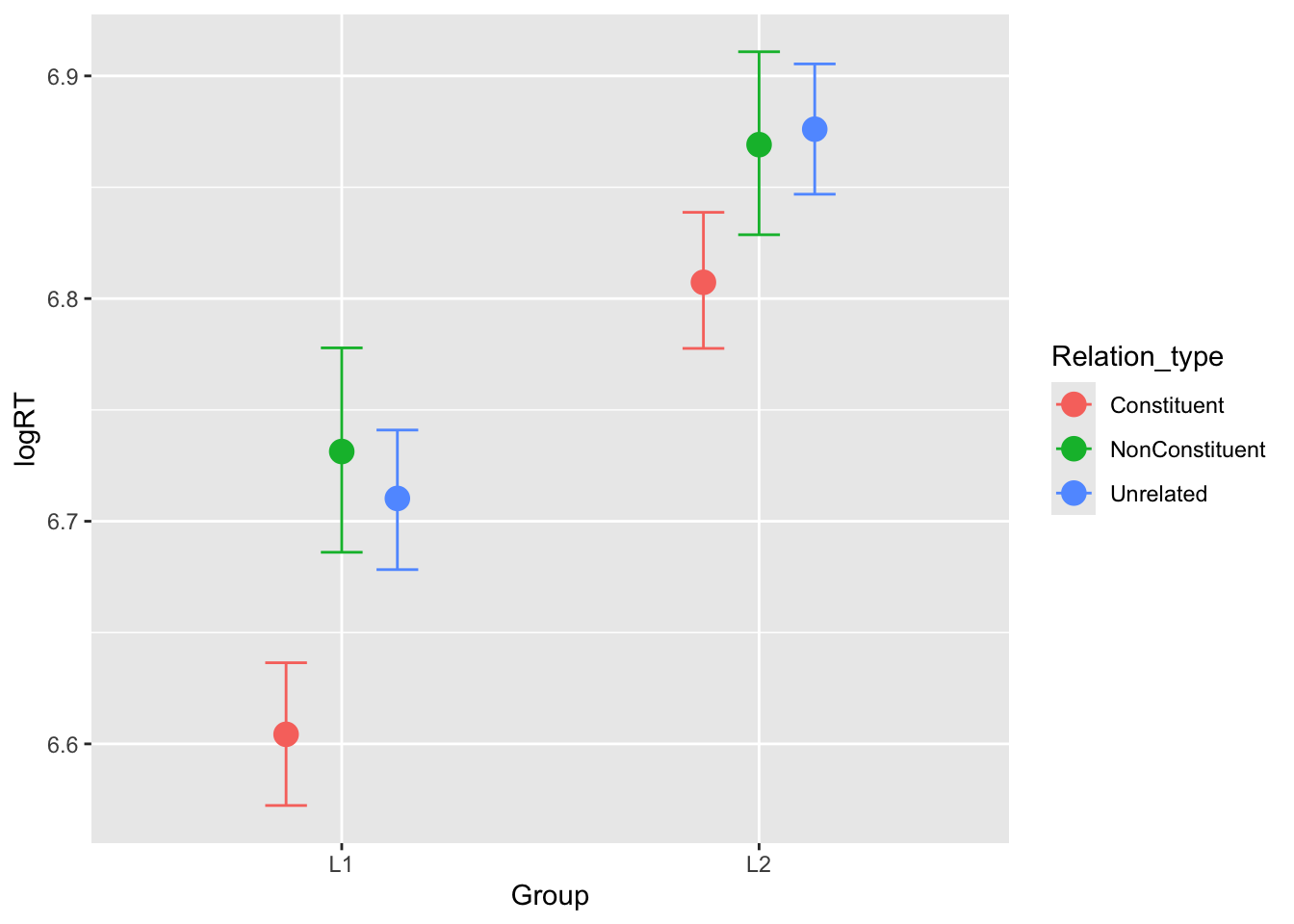
We can easily plot this with conditional_effects(), like so.
Inspection of the estimated RTs for each relation type in the two groups suggests the difference between constituent and non-constituent/unrelated is larger in L1 than in L2 participants. Let’s calculate the difference in the two groups and then the difference between these differences.
4 Get the difference of differences
As usual, we need to obtain the posterior draws.
shallow_bm_draws <-as_draws_df(shallow_bm)
Now, to get the difference between constituent and non-constituent/unrelated:
We must first get the mean of the non-constituent and unrelated relation types.
Then we can take the difference between the exponentiated posterior draws of the constituent type and the exponentiated posterior draws of the mean non-constituent/unrelated type. The exponentiation transforms the draws from logged ms to ms and then we take the difference.
Finally, we take the difference between the calculated differences in ms.
Run the code and inspect the shallow_bm_diff tibble to understand what is going on.
shallow_bm_diff <- shallow_bm_draws |>mutate(# 1. Mean non-constituent/unrelated for L1 and L2L1_NCU =mean(c(`b_Relation_typeNonConstituent:GroupL1`, `b_Relation_typeUnrelated:GroupL1`)),L2_NCU =mean(c(`b_Relation_typeNonConstituent:GroupL2`, `b_Relation_typeUnrelated:GroupL2`)),# 2. Difference between non-constituent/unrelated and constituentL1_diff =exp(L1_NCU) -exp(`b_Relation_typeConstituent:GroupL1`),L2_diff =exp(L2_NCU) -exp(`b_Relation_typeConstituent:GroupL2`),# 3. Difference of differenceL2_L1_diff = L2_diff - L1_diff )shallow_bm_diff |>select(L1_NCU:L2_L1_diff)
Warning: Dropping 'draws_df' class as required metadata was removed.
The column L2_L1_diff contains the posterior draws of the difference between the constituent and non-constituent/unrelated type in the two groups. We can proceed as usual, like with any other posterior, and calculate the CrI of this difference of differences.
Here, at 80% confidence, the difference between constituent and non-constituent/unrelated types in the L2 group is 6 to 53 ms smaller than the difference in the L1 group.